
Vue2
Vue的学习路线
原生开发
通过script标签引入vue.js,src属性通常是http链接,或者下载到本地的vue.js文件的路径。
1 | <script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script> |
如果是http链接,当浏览器加载这个脚本,会发送一个get请求获取并执行vue的js代码。
引入vue.js后,Vue这个构造函数成为全局变量,挂载到window对象上
然后我们在页面的script标签中写些代码,创建一个vue实例,传入一个配置对象
1 | const app = new Vue({ |
此时我们还未引入组件的概念,但是我们已经能够学习vue的大部分知识点了。包括模板语法,数据绑定,数据代理如何实现,vue的常用指令,计算属性,数据监听,vue的生命周期等等。
非单文件组件
什么组件?组件化开发有什么好处?
在vue中,组件就是能实现局部功能的html,css,js代码的集合,组件化开发有利于代码复用,提高开发效率,同时把功能上密切相关的html,css,js代码放到一起,依赖关系明确,易于维护。
vue的组件可分为单文件组件和非单文件组件
- 非单文件组件就是通过Vue.extend({}),返回一个VueComponent构造函数
- 这个构造函数被用来创建组件实例,依赖的配置对象就是
Vue.extend({})传入的对象 - 这个配置对象的结构,和
new Vue()传入的配置对象的结构几乎一致。 - 存在如下关系,即
Vuecomponent是Vue的子类。
1 | 组件实例._proto_ = VueComponent.prototype |

非单文件组件使用
1 | <div id="app" :name="str"> |
1 | //定义一个school组件 |
单文件组件
单文件组件就是我们熟知的.vue文件, 单文件组件解决了非单文件组件无法复用css代码的问题,我们开发过程中使用的最多的组件也是单文件组件。
显然,.vue文件是vue团队开发的文件,无法在浏览器上运行,所以我们需要借助模块化打包工具webpack来处理这个文件,webpack又是基于nodejs的,nodejs是使用模块化开发的。这样vue的开发就过渡到了基于nodejs+webpack的模块化开发,为了简化模块化开发过程中webpack的配置,vue团队就开发了vue-cli,即vue的脚手架
单文件组件的大致结构如下:
1 | <template> |
其中
export default {}由export default Vue.extend({})简化而来的,组件注册的时候会自动处理:如果发现注册的组件是一个对象,而不是一个VueComponet构造函数 ,则使用Vue.extend包裹,否则直接注册。组件之间通过嵌套确定层级关系,所有其他组件都在根组件App.vue内,根组件直接嵌入
index.html文件,这一嵌入操作是在main.js中实现的组件化开发后不需要直接在html页面中写结构,内容被分解为一个一个vue组件中的模板。
render函数
你们有没有思考过这个问题,render函数是如何得到的,调用render函数到底做了什么?
引言
1 | //子组件 |
1 | //父组件 |
上述父组件模板template,最终会被编译为如下渲染函数render(在$mount方法中,在后文有介绍):
1 | function render(createElement) { |
可以看出渲染函数中有许多createElement函数。
在创建组件根实例的时候,使用的render函数中,也用到了createElement函数,就是下面的h,不过这个render函数相当于是用户自定义的,而不是模板解析后得到的,结构非常简单。
1 | import Vue from "vue"; |
import一个App组件,得到的到底是个啥?打印出来可以看到,返回的App就是一个包含多个属性的,组件配置对象,包含了组件的所有信息。

我们将这个对象传入render方法,最终交给h方法来调用,h方法就是createElement方法。
CreateElement
createElement常常出现在渲染函数render中,下面举例子说明
所以createElement方法到底是个什么玩意?
createElement 是 Vue 中用于创建虚拟节点(VNode)的核心函数。
createElement大致源码如下
1 | export function createElement( |
总结:createElement 根据 tag 的不同,调用不同的方法(new VNode或者createComponent)生成 VNode
如果
tag是字符串:如果tag是HTML内置的标签:直接调用**
new VNode()**方法创建VNode1
2
3
4
5
6
7
8vnode = new VNode(
config.parsePlatformTagName(tag),
data,// 节点的数据对象,包含属性、事件等
children,// 子节点数组或单个子节点
undefined,//文本内容,这里为undefined因为不是文本节点
undefined,
context//当前的Vue实例上下文
);如果tag是已注册的组件标签,则拿到对应的组件构造器Ctor,虽然通常情况是一个js对象(组件的配置对象),然后再调用
createComponent方法1
2
3
4
5
6if ((Ctor = resolveAsset(context.$options, 'components', tag))) {
// 如果 tag 是已注册的组件,则创建组件类型的 VNode。
// resolveAsset 函数用于从当前Vue实例的选项中查找名为 'tag' 的组件
// Ctor是组件的构造器,虽然通常情况是一个js对象,还需要在createComponent中进一步处理
vnode = createComponent(Ctor, data, context, children, tag);
}如果tag是一个js对象(组件配置对象),比如导入App.vue得到的App,则直接调用
createComponent方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35vnode = createComponent(tag, data, context, children);
`new VNode()`的作用很明显,就是创建一个VNode;从总结中可以看出,传入`createComponent`的是一个**组件配置对象**,那`createComponent`的作用是什么,**如何处理类似App这样的组件js对象?**
### createComponent
createComponent 是**用于创建组件类型VNode**,**它最终也会调用`new VNode()`返回据组件的VNode**。大致源码如下
```js
// src/core/vdom/create-component.js
export function createComponent(Ctor, data, context, children, tag) {
// 如果 Ctor 未定义,则直接返回。
if (isUndef(Ctor)) {
return;
}
// 获取 Vue 的基础构造器,通常是指向 Vue 本身。
const baseCtor = context.$options._base;
// 如果 Ctor 是一个对象,则通过 Vue.extend 方法扩展它,使其成为一个真正的组件构造函数。
if (isObject(Ctor)) {
Ctor = baseCtor.extend(Ctor); // 使用 Vue.extend 创建子类构造函数
}
// 初始化 data 对象,确保其存在。
data = data || {};
// 实例化 VNode 并返回。注意,组件 VNode 没有 children。
const name = Ctor.options.name || tag;
const vnode = new VNode(
//tag属性,用来区别是组件类型的VNode,还是普通VNode,这里以vue-component-显然是组件类型的VNode
`vue-component-${Ctor.cid}${name ? `-${name}` : ""}`,
data,undefined,undefined,undefined,context,
{ Ctor, propsData, listeners, tag, children },//提取出的 propsData 被传入组件 VNode 的 componentOptions 中
asyncFactory
);
return vnode;//最终返回一个vnode,这个vnode就是组件的vnode
}
createComponent 在这里主要做了2件事
把传入的组件配置对象,使用
Vue.extend构造成VueComponent构造函数,我们书写组件的时候是这样的1
2
3
4
5
6
7
8import HelloWorld from "./components/HelloWorld";
export default {
name: "app",
components: {
HelloWorld,
},
};导入的
HelloWorld是一个对象,因为是个对象,所以代码逻辑会走到Ctor = baseCtor.extend(Ctor)在这里baseCtor是Vue构造函数。 然后执行baseCtor.extend将我们传入的对象,转化为构造函数。实例化
VNode并返回:在createComponent中,最终还是要调用new VNode()方法创建一个组件VNode并返回,同时我们创建好的组件的构造函数也会被传入。不过createComponent创建的不是真正的组件的vnode,而是占位的vnode,这个vnode不描述任何的真实dom结构,它告诉Vue这里要插入一个组件,包含了创建组件所需的所有信息。组件真正的、描述其内部模板结构的 VNode,是在组件实例化后,通过
render()函数生成的vm._vnode
Vue.extend()
这个api我们在学习非单文件组件的时候就学习过,下面是简要的源码
1 | Vue.extend = function (extendOptions: Object): Function { |
Vue.extend()的主要作用就是:
- 根据传入的组件配置对象,创建一个组件构造函数并返回
- 这个组件构造函数的名称是
VueComponent,然后使用原型链继承使其成为Vue构造函数的子类
调用VueComponent构造函数,就开始了组件实例的创建和初始化流程。
不过这个构造函数,不是在createComponent中被直接调用的,而是挂载到createComponent返回的VNode中,也就是组件的VNode中
具体来说,子组件的 VNode 包含了一个特殊的 componentOptions 属性,其中包含了子组件的构造函数,以及其他相关信息如 propsData, children 等。
1 | const vnode = new VNode( |
那这个构造函数具体是何时被调用呢?
调用父组件的render函数的时候,就会调用这个构造函数,开启子组件实例的创建吗?并不会!父组件调用render的时候,只会创建子组件的VNode,创建子组件的构造函数,但是不会调用子组件的构造函数。只有当父组件调用_update方法,将虚拟DOM转化成真实DOM的时候,在createEle方法(将虚拟DOM转化成真实DOM)中,才会调用子组件的构造函数,创建组件实例。
创建组件实例的时候又发生了什么?
1 | const Sub = function VueComponent (options) { |
这部分内容在《说说Vue实例挂载过程中发生了什么》中有介绍。
总结
传入createElement的是一个标准的html标签:直接调用new VNode()创建虚拟DOM
如果传入createElement是一个已经注册的组件名:先找到这个组件对应的配置对象,再调用createComponent方法:
- 先调用
Vue.extend()方法,将这个组件配置对象转化成VueComponent构造函数, - 再调用
new VNode(),传入生成的VueComponent构造函数,创建组件VNode。
如果传入createElement是一个组件配置对象,直接调用createComponent方法
说说vue2响应式是如何实现的
响应式指的是,当更改响应式数据时,视图会随即自动更新,但是响应式是如何实现的呢?
在vue2中,使用object.defineProperty来监听对象属性的变化:访问对象的属性会触发getter,修改对象的属性会触发setter,但是这还不足以实现响应式,我们还需要在gette中收集依赖,在setter中通知依赖更新,问题是依赖存储在哪儿?
在vue2中,为响应式对象的每个属性都创建了一个Dep实例,用来管理属性的依赖,属性的依赖存储在dep.subs数组中,同时这个dep实例还有管理属性依赖,通知依赖更新的方法。
tips:好了现在我们知道依赖收集在哪儿了,但是依赖到底是个什么东西?依赖就是我们数据变化后需要通知的对象,就是使用了我们数据的对象,而使用一个数据的地方有很多,比如模板中和用户定义的watch。
在vue2中,依赖有个好听的名字:Watcher。在vue2中,依赖被抽象为一个Watcher类。创建Watcher实例,在构造函数内部就会触发getter,然后这个Watcher就会做为依赖被dep收集。
defineReactive
1 | const obj = { name: 'tom', age: 22 } |
defineReactive方法内部到底做了些什么呢?其实它主要就做了如下工作:
调用observe方法递归添加响应式
为每个属性(key)都创建一个Dep实例,用来管理这个响应式数据的依赖
劫持属性,这是通过
Object.defineProperty实现的- 触发getter的时候,调用
dep.depend(),进行依赖收集 - 触发setter的时候,调用
dep.notify,通知所有订阅者更新
- 触发getter的时候,调用
Observer
1 | class Observer { |
在Observer类的构造器中:
将obj赋给
this.value创建了Dep实例:这个
Dep实例主要是为了处理数组类型的对象,或对象本身作为一个整体被访问的情况。对于数组,Vue 重写了某些数组方法(如push,pop等),以便在调用这些方法时也能够触发依赖的更新。def(obj, '__ob__', this)的作用是,将这个Observer实例,赋给这个obj的__ob__属性,这样使用obj.__ob__.dep就能管理obj这一整个对象的订阅者。调用
this.walk方法,将value转化成响应式数据。在walk方法内部:调用
Object.keys方法获得这个对象自己的所有可枚举属性然后对每个属性都调用
defineReactive方法添加响应式
observe
1 | function observe(value) { |
observe方法的实现思路很简单:
- 如果value不是对象则直接返回
- 如果是响应式对象直接返回它的observer实例
- 如果是普通对象,调用
new Observer将其转化成响应式的然后返回其observer实例。
Dep
在前面的内容中,我们发现在Observer类的构造函数中,还有defineReative函数中,都使用到了Dep类,调用了主要Dep实例的dep.depend,dep.notify()方法,那它到底有什么作用呢?
1 | let uid = 0 // 用于生成 Dep 实例的唯一 ID |
Dep.target
Dep.target表示当前活跃的(正在收集依赖的)Watcher实例,同时只能有一个
subs
每个dep实例都有唯一的id和subs(订阅者数组,Watcher数组)
dep.depend
当响应式数据的getter被触发后,这个方法就会被调用,但是这个方法其实是在调用Dep.target.addDep(this)方法,调用Watcher实例的方法,其中传入的this就是dep实例。
总的来说,dep.depend() 方法,通过利用全局变量 Dep.target,在数据读取时建立了 Dep和 Watcher之间的双向关联。具体的来说,是Watcher先进行依赖收集,然后dep再收集它的订阅者(Dep.target,当前正在收集依赖的Watcher)
dep.notify
当响应式数据改变的时候,调用这个方法通知订阅者更新,遍历并调用每个订阅者(Watcher)的 update 方法
Watcher
Watcher就是我们所说的依赖,大致源码:
1 | class Watcher { |
构造函数
接收几个参数:
vm: 当前 Vue 实例expOrFn: 要监听的内容,可以是一个字符串'a.b.c'或一个函数(计算属性的时候)cb: 数据变化时要执行的回调函数options: 可选配置项(如 deep、lazy、sync)isRenderWatcher: 是否是渲染 watcher(也就是用来更新视图的那个)
vm._watchers,是一个数组,存放这个组件中所有的 watcher:
- 渲染 watcher(1个)
- 用户通过
$watch添加的 watcher(多个) - computed 属性对应的 watcher(多个)
getter
getter函数的作用就是访问响应式数据,触发依赖收集(dep.depend),并返回一个值value
1 | if (typeof expOrFn === 'function') { |
当expOrFn是函数的时候,比如:
1 | new Watcher(vm, function () { |
那么 this.getter 就是这个函数本身:
1 | this.getter = function () { |
当expOrFn是字符串:
1 | new Watcher(vm, 'a.b.c', cb) |
Vue 内部会调用 parsePath('a.b.c') 把它转换成一个函数:
1 | this.getter = function () { |
不管expOrFn是函数还是字符串路径,最后都会变成一个能从vm取值并返回的函数,这就是 getter
get
1 | this.value = this.lazy ? undefined : this.get() |
如果不是 lazy watcher(不是计算属性Watcher),创建Watcher的时候就立即执行一次 get() 方法,收集依赖并保存初始值。
创建除了计算属性Watcher以外的所有Watcher时,都会调用立即get函数,其实get方法不仅会再构造函数中被调用,还会在run方法中被调用。
get函数到底是什么,它做了什么事情?
1 | // Dep类中的代码 |
1 | get () { |
分析上述代码,我们可以得知get方法无非就做了这么几件事:
- 调用
pushTarget(this),把当前Watcher(调用get方法的Watcher)设置为target( Dep.target = this) - 调用getter方法更新value触发依赖收集,
Dep.target就会被deps收集到subs里 - 所有依赖收集结束后,调用
popTarget()修改Dep.target,结束依赖收集。
简而言之,get能确保当前Watcher的所有依赖,都能收集到这个Watcher,同时还会返回最新的值
update
当响应式数据修改,会触发setter,调用dep.notify方法通知所有Watcher更新,遍历调用Watcher的update方法,那么这个方法做了什么?
1 | update () { |
run
在update方法中,调用run() 执行的是真正的更新过程。
1 | run () { |
从上面的代码中可得知,run方法无非就做了这么几件事:
- 调用
get更新当前值(this.value),这意味着会调用getter - 如果满足判断条件,执行回调函数cb
Watcher分类
每个Watcher都有value,getter,get,cb,update,run属性。Watcher又可分为三类,渲染Watcher,计算属性 Watcher,用户自定义Watcher。为什么Watcher只有这3类,因为响应式数据,通常只在,模板,计算属性,watch中被使用。
这三类Watcher的value,getter和cb分别是什么情况呢?首先我们可以看看这三类Watcher是在哪里,如何被创建的。
渲染Watcher
渲染 Watcher在mountComponent(后面会介绍)方法中被创建
1 | Vue.prototype.$mount = function(el){ |
可以看到第5个参数 为 true /* isRenderWatcher */; 说明是渲染watcher;updateComponent 是第二个参数,那么它应该是 expOrFn,最终会赋值给this.getter;cb是noop,就是空回调函数的意思。对于渲染Watcher来说,没有实际的回调函数cb
既然**updateComponent是渲染Watcher的getter,那它是如何触发依赖收集的**?返回值又是什么?
_render
我们先来看看updateComponent中调用的_render方法:
1 | Vue.prototype._render = function () { |
这个方法主要做了这么几件事:
- 从
vm.$options中拿到准备好的render函数(render函数由模板解析得到) - 调用render函数并返回得到的VNode
补充:
vm.$createElement就是我们常说的createElement方法。render方法其实就是使用createElement来创建VNode
render方法中会访问响应式数据(如 this.age)
1 | function render(createElement) { |
调用render方法 →响应式数据被访问 → 触发 getter → 收集依赖,因此updateComponent是一个规范的getter,它确实能触发依赖收集
_update
调用完render方法得到VNode后,还会调用_update方法,将虚拟DOM转化成真实DOM。
1 | Vue.prototype._update = function (vnode) { |
其中vm.__patch__就是我们常说的patch方法,在后面的diff算法中有介绍。
从中可以看出update方法并没有返回值(或者说返回值是undefined),这就意味着updateComponent方法没有返回值,这就意味着渲染Watcher的getter没有返回值,这就意味着渲染Watcher的value始终是undefined,也就是说,渲染Watcher的value不重要
总结
- 渲染Watcher没有cb,只有getter;而且getter没有返回值,说明渲染Watcher的value不重要,更新后只触发getter
- 如果响应式数据在模板中被使用,当创建渲染Watcher的时候,会在构造函数中调用
this.get方法:this.get内部会调用pushTarget(this),将渲染Watcher设置为target(将渲染Watcher赋给Dep.target)- 再调用
this.getter方法,也就是updateComponent方法。 - updateComponent方法内部会调用render方法,访问响应式数据,触发getter
- 调用
dep.depend()方法,其在内部调用Dep.target.addDep(this)方法,让渲染Watcher订阅dep,addDep方法内部调用dep.addSub(this),让dep收集渲染Watcher到subs。 - 调用完render方法,收集好依赖,返回虚拟DOM后,
updateComponent还会调用update方法,将虚拟DOM转化成真实DOM
- render方法只在
this.get中被调用,而渲染Watcher调用get方法的时候,就会将渲染Watcher赋给Dep.target,所以调用render方法的时候,deps收集的Watcher一定是渲染Watcher
计算属性Watcher
在initComputed中已介绍,不赘述
用户自定义Watcher
在initWatch中已介绍,这里再补充几点:
用户自定义Watcher的
user属性为true用户自定义Watcher区别于前面2类Watcher,它有自己的
cb,是用户定义的,当自定义Watcher的依赖更新后,用户自定义的Watcher就会调用update->run方法,然后在run方法中调用cb1
2
3
4
5
6
7
8if (this.user) {//用户定义的watcher,就是通过watch配置的,自定义的watcher
const info = `callback for watcher "${this.expression}"`
//执行回调函数(带错误处理),并传入参数
invokeWithErrorHandling(this.cb, this.vm, [value, oldValue], this.vm, info)
} else {
//执行回调函数,并传入参数
this.cb.call(this.vm, value, oldValue)
}我们自定义Watch的时候还能拿到新旧值,这说明对于用户自定义Watcher,它的value也是有意义的。
对比
| Watcher 类型 | update() 是否调用 run()? | 是否有回调 cb? | 如何处理更新 | 何时被创建 |
|---|---|---|---|---|
| 渲染 Watcher | 是 | 否(内部机制处理更新) | 放入队列,最终调用 run() 更新视图 | 在mountCompnent方法中 |
| 用户 Watcher(watch 选项) | 是 | 是 | 放入队列,调用 run() 执行回调 | 在initWatch的时候 |
| 计算属性 Watcher | 否 | 否 | 仅标记为 dirty = true,下次访问时重新计算 | 在initComputed的时候 |
给对象添加属性视图不刷新
由于我们在vue2中是基于Object.defineProperty()来实现的响应式的,所以添加或者删除对象的属性,或者通过数组方法修改数组,无法被vue监听到。
Vue对此也提供了解决的方案。
对于数组,编写拦截器对象,重写数组原型上那7能修改数组的方法:pop,push,shift,unshift,sort,reverse,splice,然后使用拦截器覆盖掉哪些需要添加响应式的数组的原型。之后调用该数组的那几个方法,使用的就不是数组原型上的方法,而是重写的方法,在重写的方法中,通知数组的依赖进行更新。
1 | function def(obj, key, value, enumerable) { |
对于对象,Vue提供了vm.$set和vm.$delete方法来解决这个问题,关于二者已经介绍过。
说说new Vue()后发生了什么
我们都听过知其然知其所以然这句话
那么不知道大家是否思考过new Vue()这个过程中究竟做了些什么?
过程中是如何完成数据的绑定,又是如何将数据渲染到视图的等等。下面给出简要流程:
在构造函数中调用
_init方法在
_init方法内部:- 做一些初始化工作
- 调用
beforeCreate钩子 - 初始化
Injections - 初始化
state - 初始化
Provide - 调用
created钩子 - 调用
vm.$mount方法
在
initState方法内部,依次调用:initPropsinitMethodsinitDatainitComputedinitWatch
在
initData方法内部- 检查data中的属性,是否和props和method中的属性有冲突
- 调用proxy方法,把数据代理到this上,简化访问路径
- 调用observe方法,给数据添加响应式
在
initProps方法内部创建一个空对象,赋值给
vm._props校验props中的key是否合法,得到一个value
把这个value和对应的key,响应式地添加到
vm._props,最终代理到vm。
vue构造函数
首先找到vue的构造函数
1 | //源码位置:src\core\instance\index.js |
options是用户传递入的配置对象,包含data、methods等常用属性。
vue构建函数调用了_init方法,并传入了options,所以我们关注的核心就是_init方法:
_init
1 | //位置:src\core\instance\init.js |
在调用beforeCreate之前,主要做一些数据初始化的工作:
initLifecycle的作用就是初始化vm.$parent,vm.$root(组件的根组件),vm.$children,vm._watcher等属性。initEvents是用来初始化事件的,初始化的是父组件给子组件添加的事件。本质是通过vm.$on来给子组件实例添加事件监听,被注册的事件会存储在vm._events对象中,后续移除事件监听则是通过vm.$off,这两个api我们都介绍过。子组件模板内添加的事件,至少需要在模板解析后才能开始初始化。
callhook的作用是触发用户设置的生命周期钩子,用户设置的options最终会和构造函数的options属性合并,然后赋值给vm.$options,所以我们可以通过vm.$options得到用户设置的生命周期函数
initInjections和initProvide在后文传值方式中有介绍,initInjections 在 initState 之前执行,所以在data或者props中可以使用this访问inject中的数据。initProvide 在最后执行,所以它能使用data中的数据。
initState
1 | //源码位置:src\core\instance\state.js |
分析后发现,initState方法依次,统一初始化了props/methods/data/computed/watch,说明在created的时候,这些东西都准备好了,或者说初始化工作都完成了。
initProps
1 | function initProps(vm, propsOptions) { |
propsOptions = vm.$options.props,是props配置对象,是我们自定义的,比如
1 | props:{ |
vm.$options.propsData,是组件接收到的,父组件传递过来的值。vm._props的值起初是一个普通的空对象,后来被响应式的添加了属性,最后它的属性会被代理到vm上(如果vm上步存在同名属性的话)。
initProps无非就是做了这么几件事:
- 创建一个空对象,赋给
vm._props - 使用
propsOptions校验propsData,并拿到一个一个的值value - 调用
defineReactive(props, key, value),将一个一个的值响应式地代理到vm._props上,区别于inject直接把key,value响应式的添加到vm上。 - 如果
props中的某个key在vm上不存在,则调用proxy(vm, '_props', key),将其代理到vm上,然后就能直接通过vm访问vm._props上的值。
initMethods
简要源码如下:
1 | // 简化自 Vue 2.x 的源代码 |
实现思路如下:
- 遍历methods中的所有key,如果值不是一个函数则报错
- 如果methods中的key和props中的key重复,也报错
- 如果methods中的key已经在vm中存在了,且是以
$或者_开头的,则也报错 - 如果不存在上述问题,使用bind修改方法中this的指向,将修改后的方法挂载到vm上
initData
1 | function initData (vm: Component) { |
阅读源码后发现:
props和method在data之前就被初始化了,所以data中的属性值不能与props和methods中的属性值重复;之所以要防止重复,因为它们都会被代理到this(vm)上(是的,包括props中的数据),都是直接通过this来访问,重复了就会产生冲突。
同时我们也可以发现,props中的数据的优先级是高于data中的数据的,对于data中的key,只有在props中不存在相同的key的时候,才能代理到vm上。
vue的数据代理核心在于proxy方法,我们来看看它做了什么
proxy
1 | function proxy(target, sourceKey, key) { |
再次之后,访问target.key返回的就是target.sourceKey.key,说到底还是从target上面取数据,只不过简化了访问的路径。
vue给数据添加响应式的核心在于observe方法,我们来分析一下这个方法
initComputed
计算属性的配置方式有2种。
1 | new Vue({ |
initComputed的简要源码:
1 | function initComputed (vm: Component, computed: Object) { |
我们来看看initComputed到底做了什么:
遍历每个计算属性,在给每个计算属性创建Watcher之前,先确定每个计算属性的getter,这一点非常简单。拿到每个计算属性的value,如果这个value是一个函数,则直接把它作为计算属性Watcher的
getter,否则把value.get作为getter,无论如何,得到的getter的格式形如:1
2
3function() {
return this.firstName + ' ' + this.lastName;
}可以看出,计算属性的
getter的主要作用是求值,由于访问了响应式属性还会触发依赖收集,作为Watche的getter非常合适。确定好
getter之后,为每个计算属性创建一个Watcher,并存储在vm._computedWatchers[key]中,从代码中可以看出,计算属性Watcher也没有实际的回调函数cb,它的cb是一个空函数(noop),说明计算属性Watcher的cb不重要。对于 计算属性(computed) 来说,它对应的 Watcher 有两个特殊标志:
lazy:表示是否延迟求值(即在构造函数中不立即调用
get()方法获取值)dirty:表示当前值是否是“脏”的(需要重新计算)
因为计算属性Watcher的lazy属性为true,这就是意味着,创建计算属性Watcher的时候,并不会立即调用
this.get方法取值,也就不会触发收集依赖。只有在模板或其他地方访问它的时候才会真正去求值1
2
3constructor (){
this.value = this.lazy? undefined: this.get()
}
创建完计算属性的Watcher后,调用
defineComputed方法
defineComputed
我们再来看看defineComputed到底做了什么
1 | // 辅助变量和函数 |
可以看出,defineComputed的最终目的是,使用Object.defineProperty,把计算属性代理到vm上方便访问的,但是在这之前,还需要确定计算属性的get和set:
- 计算属性的
get等于createComputedGetter(key) - 计算属性的
set等于userDef.set,如果没有配置set,则set为noop,空函数。
createComputedGetter
createComputedGetter这个函数的命名意思非常明确,它的作用就是用来创建计算属性的getter的,我们来看看createComputedGetter是如何构造计算属性的get的
1 | // 创建 computed 属性的 getter 函数 |
createComputedGetter会立即返回一个具名函数computedGetter,意思就是计算属性的getter,在computedGetter 函数的内部,或者说计算属性get的内部,是这样工作的:
先在
this._computedWatchers中查找当前key(计算属性)是否存在对应的watcher,不存在直接退出找到计算属性的Watcher后,根据
Watcher.dirty属性判断计算属性是否是脏的,如果是,则调用watcher.evaluate()如果有Watcher正在收集依赖,则调用
watcher.depend()方法最后,返回
watcher.value。这就说明,计算属性的get返回的值,本质就是对应的计算属性watcher.value确定计算属性的set就没那么麻烦了,如果自己定义了set,直接就当作计算属性的set。
在调用完watcher.evaluate()后,还调用了watcher.depend(),它做了什么,此时的Dep.target为什么是渲染Watcher?
如果模板中使用了计算属性,在组件首次挂载时,会经过一下流程:
1 | 创建渲染Watcher -> 调用get方法 -> 将渲染Watcher设置为Dep.target -> 调用render函数。 |
在render函数中就会访问计算属性,触发计算属性的getter,之后会发生的事情就是我们前面介绍过的:computedGetter要的做的事情:触发了依赖收集,计算属性Watcher被收集为依赖,依赖收集完毕后,Dep.target就被切换为渲染Watcher。
然后调用watcher.depend方法,遍历计算属性Watcher观测的所有dep,调用它们的depend方法,收集Dep.target,也就是渲染Watcher为依赖。
1 | //Watcher的 depend 简要源码如下 |
调用它们的depend方法
1 | //dep的depend方法 |
简单的来说,在访问计算属性时,**watcher.depend() 会让渲染 Watcher 去订阅计算属性所依赖的底层数据的 dep,而计算属性 Watcher 本身也是这些 dep 的订阅者。因此,这些 dep 的 subs 列表中会同时包含计算属性 Watcher 和渲染 Watcher。**
这么做的效果就是,如果某个计算属性在模板中使用了,当其某个依赖的改变后,会同时通知计算属性Watcher更新和渲染Watcher更新;
对于一般的数据来说,触发getter就是返回闭包中的value(defineReactive中的第三个参数),然后触发依赖收集。
1 | const obj = { name: 'tom', age: 22 } |
但是对于计算属性来说,触发getter返回的是对应的计算属性Watcher的value;如果对应的Watcher属性为脏(dirty:true)的话,还会触发依赖收集,但是是计算属性Watcher和计算属性依赖的值,这二者之间的依赖收集,和这个计算属性属性本身没有关系。
也就是说,计算属性虽然会被代理到vm上,就像一般普通响应式数据一样,但是计算属性没有自己的dep。其实从代码的角度也可以理解,只有通过defineReactive响应式添加的属性才有自己的dep,而计算属性是直接使用Object.defineProperty添加到vm上的。
而且收集依赖的目的是数据被更改后触发依赖更新,而修改计算属性触发的setter,是用户自定义的,怎么会有通知依赖更新的逻辑。
变动
这种设计看起来完美,但是还存在问题,如果计算属性依赖的状态改变了,但实际的值没有改变,渲染Watcher还是会被通知去更新。
解决的办法就是,计算属性依赖的状态,不再收集渲染Watcher为依赖。对于计算属性Watcher,实例化的时候还会有如下初始化操作:
1 | this.dep = new Dep |
哈哈,在Watcher中创建dep,完美解决了计算属性没有自己dep的问题,后续计算属性的值真正改变了的时候,计算属性Wacther再通知渲染Watcher更新
initWatch
在vue2中,watch的注册方式有多种:
1 | watch:{ |
initWatch的实现思路并不复杂,因为我们之前研究过vm.$watch的实现方法。
1 | function initWatch(vm, watch){ |
initWatch接收2个参数,vm是组件实例,watch是用户设置的watch对象。使用for in 遍历watch对象,其中的每个key就是路径字符串,对应的值的类型大致可以分为2类,数组和非数组。如果是数组,对数组中的每一项都调用createWatcher,如果不是数组直接调用createWatcher。
vm.$mount
在本文中介绍过了,不赘述
Vue的实例方法
vm.$set
1 | vm.$set(target, key, value) |
用法:设置对象的属性,如果对象是响应式的,确保属性被创建后也是响应式的,同时触发视图更新。这个方法被用来解决在vue中给对象添加属性无法被监听到的问题。
实现原理:
1 | function set(target, key, value) { |
实现思路:
- 先考虑target是数组的情况,使用splice来实现,由于在vue中数组方法被拦截了,所以通过数组方法修改数组能被监听到。
- 如果target是对象的情况,获取这个对象的
__ob__属性,如果这个属性不存在,说明这个对象是普通的对象,直接添加对应的key,value即可 - 如果target是响应式对象,通过
defineReactive方法将key,value响应式的添加到target上,并通知target的依赖进行更新。
vm.$delete
1 | vm.$delete(target, key) |
用法:删除对象的属性。如果对象是响应式的,确保删除能触发更新视图。这个方法主要用于避开vue.js不能检测到属性被删除的限制。
实现原理:
1 | function delete(target, key) { |
实现思路:
- 同样的,先考虑target是数组的情况,使用splice方法来删除对应的属性,由于在vue中数组的方法被拦截了,所以调用数组方法修改数组能被监听到。
- 再考虑target是对象的情况,如果这个对象不是响应式的,直接删除这个属性即可,如果是响应式的,删除属性后,还要通知这个对象的依赖更新
vm.$watch
1 | //第一个参数可以是路径字符串也可以是函数 |
返回值是unwatch函数,用于解除事件监听。
1 | const unwatch = vm.$watch('a.b.c', function(newVal, oldVal){ |
实现原理:
1 | function $watch(expOrFn, cb, options) { |
vm.$watch其实是对Watcher的一种封装,Watcher的原理在前面介绍过。如果options中还配置了deep:true,在创建对应的Watcher实例的时候,实例的deep属性会被标记为true,然后在get方法中,不仅会调用getter方法获取到value,还会递归访问value的子值。
1 | get(){ |
vm.$on
1 | vm.$on(event, cb) |
用法:监听当前实例上的自定义事件,事件可由vm.$emit触发,下面介绍简要的实现原理:
1 | const obj = {} |
vm.$off
1 | vm.$off([event, callback]) |
用法:移除实例上的自定义事件监听器。
- 如果没有提供任何参数,则移除实例上的所有事件监听器
- 如果只提供了事件,则移除该事件的所有的监听器
- 如果同时提供了事件和回调,则只移除这个回调的监听器
简要实现原理如下:
1 | obj.__proto__.$off = function (event, cb) { |
vm.$once
1 | vm.$once(event, callback) |
用法:监听一个自定义事件,但是只触发一次,在第一次触发之后移除监听器
实现原理:
1 | obj.__proto__.$once = function (event, cb) { |
vm.$emit
1 | vm.$emit(event,[...args]) |
用法:触发当前实例上的自定义事件,附加的参数都会传入对应的回调函数。
1 | obj.__proto__.$emit = function (event, ...args) { |
vm.$forceUpdate
vm.$forceUpdate的作用是强迫vue.js实例重新渲染,注意它仅仅影响实例本身和插入插槽的子组件,而不是所有子组件。
1 | Vue.prototype.$forceUpdate = function(){ |
简单来说,vm.$forceUpdate的作用就是手动调用渲染Watcher的update方法
vm.$destroy
vm.$destroy的作用是完全销毁一个实例,它会清理该实例和其他实例的连接,并解绑其全部指令和监听器,同时会触发beforeDestory和destroyed这2个钩子函数。
1 | Vue.prototype.$destroy = function(){ |
vm.$mount
这个方法通常不需要我们手动调用,因为如果在实例化的时候设置了el选项,会自动把vue.js实例挂载到dom元素上,其实内部其实使用的就是这个方法。如果vue.js实例在实例化的时候没有收到el选项,则它处于未挂载的状态,没有与html文件关联,我们可以手动调用vm.$mount方法将vue.js实例挂载到dom上。
1 | const MyComponent = Vue.extend({ |
vue.js其实有很多不同的构建版本,在不同的构建版本中,vm.$mount的表现都不一样,主要区别体现在完整版(vue.js)和运行时版本(vue.runtime.js),这二者的差异在于,完整版中有编译器,可以编译模板为渲染函数,而运行时版本中没有编译器。
在完整版的vue.js中,vm.$mount会先检查渲染函数render是否存在,如果没有立即进行编译过程,将模板编译成渲染函数;而在运行时版本中,由于没有编译器,它会默认实例上已近存在渲染函数,如果不存在,为了防止报错,会将创建空注释结点的函数,作为渲染函数。
下面介绍完整版vm.$mount的代码
1 | const mount = Vue.prototype.$mount |
在上面代码中,我们将vue原型上的$mount方法保存在mount中,以便后续使用。然后就把vue原型上的$mount方法给覆盖了。新方法会调用原始的方法,这种做法叫做函数劫持。
通过函数劫持,可以在原始功能上新增其他功能,上述代码中,mount方法就是vm.$mount方法的核心功能,我们把它保存下来了。在完整版中,需要在mount功能的基础上添加编译的功能
1 | const mount = Vue.prototype.$mount |
1 | function query(el){ |
query函数的功能在于根据el的类型不同,返回对应的dom。如果el是字符串,则将其视为选择器捕获对应的dom并返回,如果没有捕获到则返回一个空的div;如果el不是字符串,则视为dom直接返回。
接下来将实现完整板vm.$mount中的核心功能:编译器
1 | const mount = Vue.prototype.$mount |
1 | function idToTemplate(id){ |
编译器的工作流程:
检查是否存在
render函数,如果存在,则直接调用mount方法如果没有
render函数,则将模板编译成render函数:需要先拿到模板:
判断配置对象中是否有
template属性,我们期望是一个html字符串,但如果这个字符串是id选择器,我们则获取对应的html结构作为模板字符串(idToTemplate)。实际还可能是dom对象,我们把这个dom对象的
innerHTML作为模板如果既没有
render也没有template,那就将el的全部结构作为template(包括了元素本身以及其内部的所有 HTML 内容)无论如何,最终
template属性的值是一个html字符串最后进行模板编译,得到
render函数,挂载到options上
接下来介绍在运行时版本的vue.js中,vm.$mount的工作原理,也就是vm.$mount的核心功能,前面介绍过,存储在mount方法中。
1 | Vue.prototype.$mount = function(el){ |
我们接下来来看mountComponent的具体实现
1 | export function mountComponent (vm, el) { |
1 | Vue.prototype._render = function () { |
mountComponent做了这么几件事
- 先判断
vm.$options.render是否存在,如果不存在的话就让它等于createEmptyVNode。 - 执行beforeMount钩子
- 准备好updateComponent,也就是渲染Watcher的getter,创建渲染Watcher
从上述代码中可以看出,在beforeMount钩子被调用的时候,模板已经编译完毕,render函数已经准备好了,不过还没有被调用。
在创建渲染Watcher的时候,在构造函数中,updateComponent会立即执行,也就是说会调用_render函数;再调用_update方法
在_update中,对于初次渲染有如下代码:
1 | vm.$el = vm.__patch__(vm.$el, vnode) |
其中vm.$el就是一个真实的dom元素,用户指定的挂载元素,比如#app,vm.$el = document.getElementById('app')。
__patch__ 的签名是:
1 | __patch__(oldVnode, vnode) |
但它能处理多种类型的 oldVnode:null,真实 DOM 元素,vnode,__patch__ 内部会判断 oldVnode 是否是真实 DOM:
1 | function patch (oldVnode, vnode) { |
随后el: '#app'对应的dom会被替换掉,新的结构会插入到el: '#app'的父元素中。
Vue的全局方法
Vue.extend
1 | Vue.extend = function (extendOptions: Object): Function { |
之所以省略了许多代码,是因为哪些代码实在是看不懂…,以后有机会再完善吧
简单的来说,Vue.extend方法就是创造了一个组件,创造了一个构造函数,这个构造函数的父类是Vue构造函数。
实现继承的思路就是:使用Object.create方法,创造一个以Vue构造函数的原型为原型对象的空对象,然后将这个空对象作为构造函数的原型,最后给这个空对象上添加constrcutor属性,指向创造的构造函数。
Vue.nextTick
用法如下:
1 | Vue.nextTick( [callback, context] ) |
用法:传入的回调函数会在下一dom更新之后延迟执行,修改数据后立即使用这个方法,在回调函数中能拿到最新的dom。
源码:
1 | import { nextTick } from '../utils/index' |
其中的nextTick方法就是后面介绍过的nextTick方法,无论是Vue.nextTick方法还是vm.$nextTick方法,都是同一个方法,都是nextTick方法,只是挂载的位置不同。
Vue.set
其用法如下:
1 | Vue.set( target, key, value) |
用法:设置对象的属性,如果对象是响应式的,确保属性被创建后也是响应式的,同时触发视图更新。这个方法被用来解决在vue中给对象添加属性无法被监听到的问题。
Vue.set和vm.$set的实现原理相同:
1 | import { set } from "../observer/index" |
都是同一个set方法,只是挂载的位置不同。
Vue.delete
其用法如下:
1 | Vue.delete( target, key) |
用法:删除对象的属性。如果对象是响应式的,确保删除能触发更新视图。这个方法主要用于避开vue.js不能检测到属性被删除的限制。
同理,Vue.delete与vm.$delete的实现原理相同,都是同一个delete方法只是挂载的位置不同。
Vue组件通信的方式有哪些
vue中,每个组件之间的都有独自的作用域,组件间的数据是无法共享的,但实际开发工作中我们常常需要让组件之间共享数据,这也是组件通信的目的,要让它们互相之间能进行通讯,这样才能构成一个有机的完整系统。
组件间通信的分类
- 父子组件之间的通信
- 兄弟组件之间的通信
- 祖孙与后代组件之间的通信
- 非关系组件间之间的通信
props传递数据
基本语法
适用场景:父组件传递数据给子组件,即父子组件之间的通信
父组件通过给子组件标签添加属性,来传递值,子组件设置props属性,接收父组件传递过来的参数,同时还能限制父组件传递过来的数据的类型,还能设置默认值。
1 | <Children name="jack" age=18 /> |
1 | //Children.vue |
注意:
- props中的数据是父组件的,子组件不能直接修改,遵循”谁的数据谁来维护”的原则。
- 子组件标签的所有属性中,未被子组件接收(props中未声明)的数据,也能在
this.$attr,即组件实例的属性中拿到,因为未被接受的属性,就会被当作组件自身的普通属性。
深入理解
再问大家一个问题,为什么父组件中的数据更新,子组件中通过props接收的数据也会随之改变,子组件视图也会更新?
1 | //子组件 |
1 | //父组件 |
父组件的模板,在模板编译的时候,会被解析成一个render函数,这一点我们在前面已经介绍过了,在上述例子中,父组件的模板解析成render函数大概是这样:
1 | function render(createElement) { |
createElement方法是用来创建VNode的,render方法返回的其实就是虚拟DOM,这一点和React中完全相同- 调用父组件的模板
render函数时,访问了父组件实例的age属性,赋值给子组件的props.age,这个过程中触发age属性的getter,于是收集父组件自身的render函数为依赖(就是渲染Watcher) - 调用父组件的模板
render函数,遇到子组件标签时,会调用createElement方法,根据子组件的配置,创建子组件的VNode(这部分内容前面介绍过) ,然后再将子组件VNode转化成真实DOM的时候,会调用子组件构造函数,创建子组件实例,这个过程会调用initProps方法。
1 | //传入的第二个参数,是子组件中的props属性的值(props配置对象) |
- 父组件传递了,且子组件通过
props接收的数据,会被存储在vm.$options.propsData - 子组件初始化的时候(调用
initProps的时候),会将通过props接收的数据,添加响应式,并代理到vm上,缩短访问路径。
上述例子中,父组件传递给子组件的值,只不过是this.age,是一个普通数据类型,压根不是响应式数据,这种传递会导致响应式丢失,触发getter的位置,也是在父组件渲染函数内,子组件渲染Watcher压根就没被age属性收集为依赖,后续是子组件自己把age属性添加到vm._props并添加响应式的(后续又代理到vm)。
既然在父组件的age属性并没有收集子组件Watcher为订阅者,为什么父组件更新age属性,子组件视图也会更新呢?
当父组件中的
age属性改变,会触发对应的setter,然后通知依赖更新,其中的依赖就包括父组件渲染Watcher父组件
渲染Watcher最终会调用run方法,这个方法会调用render函数,创建新的组件vnode(props的值是新的)在patchVnode阶段,更新组件实例,修改子组件的
_props属性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54function patchVnode (oldVnode, vnode) {
if (oldVnode === vnode) {
return;
}
//判断是否是组件 VNode
if (isRealComponent(vnode)) {
// 组件 VNode 有自己的一套 prepatch 流程
const prevComponent = oldVnode.componentInstance;
const hook = vnode.data?.hook;
if (hook && hook.prepatch) {
//这是 Vue 内部定义的一个钩子函数,用于处理组件更新逻辑
hook.prepatch(oldVnode, vnode); //在这里调用 updateChildComponent
}
return;
}
//不是组件VNode的时候的处理逻辑
//..........
}
prepatch(oldVnode, vnode) {
const options = vnode.componentOptions;
const childInstance = vnode.componentInstance = oldVnode.componentInstance;
// 👇 更新 props、listeners、插槽等
updateChildComponent(
childInstance,
vnode.propsData,
vnode.listeners,
vnode,
false
);
},
// src/core/instance/lifecycle.js
export function updateChildComponent(
vm: Component,
propsData: ?Object,
listeners: ?Object,
parentVnode: VNode,
renderChildren: ?Array<VNode>
) {
const props = vm.$options.props;
if (props) {
toggleObserving(false);
const oldProps = vm._props;
for (const key in props) {
const prop = props[key];
const newVal = validateProp(key, props, propsData, vm);
const oldVal = oldProps[key];
if (newVal !== oldVal) {
vm._props[key] = newVal; // 👈 更新 props
}
}
toggleObserving(true);
}
// 更新监听器和插槽...
}由于
this._props是响应式的,所以会自动触发子组件视图更新。
简单的来说,父组件修改传递给子组件的数据,子组件视图也会更新,**是因为父组件内部重新调用了render方法,创建了新的组件Vnode,然后在patchVnode的时候,会更新组件实例的_props属性(this._props)**。
流程:父组件修改数据 → 触发重新渲染(render)→ 创建新的组件 VNode → 在 patchVnode 阶段触发组件的 prepatch 钩子 → 调用 updateChildComponent → 更新子组件 _props → 子组件视图更新。
$emit 触发自定义事件
适用场景:子组件传递数据给父组件(父子组件通信)
子组件通过$emit触发自定义事件,$emit第一个参数为自定义的事件名,第二个参数为传递给父组件的数值
父组件在子组件上绑定事件监听,通过传入的回调函数拿到子组件的传过来的值。
1 | //Children.vue |
1 | //Father.vue |
要注意的是,给组件添加的事件监听是自定义事件,因为组件标签不是原生标签,无法添加原生事件监听,也就没有原生事件对象,所以传递给回调函数的是子组件传递过来的值,而不是原生dom事件。
在vue2中,我们只要给父组件传递数据,并给对应的属性添加sync修饰符,就能省去在给组件标签添加事件监听,书写回调逻辑,同步父组件数据的代码,在vue3中,这一功能则是通过v-model实现的,更多介绍参考本博客内的《vue》一文。
ref
在 Vue 2 中,this.$refs 是一个对象,它包含了所有通过 ref 属性注册的 DOM 元素或组件实例。可以使用 this.$refs 来直接访问这些dom元素或组件实例,从而进行操作,如获取DOM节点、调用子组件实例的方法,获取数据等。
注意:this.$refs 只能在父组件中,用来引用通过 ref 属性标记的子组件或 DOM 元素
1 | <Children ref="foo" /> |
同时,子组件也可通过this.$parent拿到父组件实例
事件总线
使用场景:兄弟组件传值
通过共同祖辈$parent或者$root搭建通信
兄弟组件
1 | this.$parent.on('add',this.add) |
另一个兄弟组件
1 | this.$parent.emit('add') //注意的是,这里不是$emit |
本质就是要找到一个两个兄弟组件都能访问到的vue实例,在这个实例上注册事件监听,同时也在这个实例上触发事件,本质和emit是一样的(父组件在子组件实例上添加事件监听,子组件通过自己的实例this调用emit方法)。这个vue实例的作用好像连接这两个组件的管道,通过这个Vue实例来通行。
provide 与 inject
基本语法
跨层级传递数据,传递方向是单向的,只能顶层向底层传递。
在祖先组件定义provide属性,返回传递的值,在后代组件通过inject,接收祖先组件传递过来的值
1 | export default { |
1 | //写法1 |
深入理解
如果父组件通过Provide传递的是一个基本数据类型,在子组件内接收了,后续即便父组件修改这个基本数据类型,子组件也不会更新,为什么?但如果父组件通过Provide传递的是一个对象,这一情况就完全不同?
我们先看看initProvide的源码:
1 | export function initProvide(vm: Component) { |
可以看出initProvide的源码非常简单:
- 如果组件定义了Provide属性,且值是一个函数,则使用
call(vm)调用这个函数,确保this指向准确。 - 最后将函数调用的返回值,其实也就是一个对象,赋给
vm._provided属性。
再看看initInjections的源码
1 | // src/core/instance/inject.js |
initInjections无非就是做了这么几件事:
从祖先元素取值:调用
resolveInject(vm.$options.inject, vm),向上查找祖先组件的_provided属性,找到匹配的provideKey,最终返回以一个result对象。大致步骤如下:创建一个空对象result,遍历inject配置对象中的每个属性,从当前组件实例开始:
检查这个组件实例是否提供了对应的值,如果提供了,则把这个值取出来,存到result中
1
result[key] = source._provided[provideKey]
如果没有找到,则继续去下一个祖先元素中查找,类似原型链查找
如果在所有祖先元素中都没有找到这个provideKey,则检查
inject[key]中是否提供默认值,如果提供了则使用默认值(是用户在inject中配置的),存到result中,如果默认值都没提供,则直接报错
将注入的值代理到组件实例上并添加响应式:使用
defineReactive(vm, key, value), 将result上的所有属性都代理到vm上并添加为响应式,但 不进行深度响应式处理(也就是在defineReactive中,调用observe方法会直接返回)。
ok,分析完源码后,我们来尝试解决开始提到的问题
所以说,即便父组件
Provide的值被修改了1
2
3
4
5
6
7provide() {
//使用data或者computed中的数据
return {
color: this.color, // 非响应式,因为this.color的值只是个普通类型
userInfo: this.userInfo, // 响应式,因为this.userInfo的值是个对象,而vue中对象是递归添加响应式的
};
}比如
this.color修改了 ,也并不会重新Provide这个值,也就是说provide是一次性的,所以如果父组件通过Provide传递的是一个基本数据类型(比如this.color),在子组件内接收了,后续即便父组件修改这个基本数据类型,在子组件实例vm上的color也不会改变。但是如果父组件通过
Provide传递的,是一个对象,由于在vue中响应式是递归添加的,所以这个对象是个响应式对象,而且由于传递的是一个引用,其实父子组件是共用这个响应式对象的,如果子组件中在模板中使用了这个对象,则子组件的渲染Watcher会被它收集为依赖,这样即便在父组件内修改这个对象,在子组件的视图也会更新。
与props的比较
写法相同
在vue2中,inject的写法和props的写法完全相同
1 | //数组写法 |
原始值相同
父组件给子组件通过传递props传递的数据,就是vm.$options.propsData,本身也不是个响应式对象,父组件provide的数据(vm._provided),也不是一个响应式的对象
1 | createElement('Child', { // 子组件 Child,绑定 props.age |
1 | provide() { |
它们本身都类似
1 | { |
也就是父组件从自己身上取值,然后存到一个普通对象身上,在这个取值的过程,其实是会丢失响应式的,但如果取出的是一个对象,比如userInfo,由于在vue中响应式是递归添加的,所以这个对象userInfo还是个响应式对象。
props
通过props传值的时候,由于是在模板中使用响应式数据,父组件的响应式数据,会收集父组件的渲染Watcher为订阅者,但是通过provide传值,真的就只是传了一个值,没有Watcher在收集依赖
后续
initProps,子组件会把propsData上的原始数据,代理到vm._props上并添加响应式,最终代理vm上方便访问。通过vm直接访问props接收的数据,数据源是vm._props,而vm._props的数据源是闭包中(defineReactive)的一个一个value1
2
3
4
5
6
7
8
9
10
11
12const props = vm._props = {};
for (const key in propsOptions) {
// 使用propsOptions校验propsData,
// value优先使用propsData中的值,如果不存在对应值或者值不符合要求,再使用propsOptions中提供的默认值
const value = validateProp(key, propsOptions, propsData, vm);
// 组件接收的属性,会被添加到vm._props上,并添加响应式(递归添加),所以vm._props是一个响应式对象
defineReactive(props, key, value);
// 代理到实例(this),然后就能直接通过this访问
if (!(key in vm)) {
proxy(vm, '_props', key);
}
}
inject
后续
initInjections,子组件从祖先组件的vm._provided上取值,并存储到result对象上,由于result单纯是浅拷贝一些祖先组件上_provide的值,所以result对象也是一个普通的对象,后续把result上的数据,直接代理到vm上并添加响应式。直接通过vm访问inject的数据,数据源也是闭包中的数据result[key]1
2
3
4
5toggleObserving(false); // 关闭深度响应式观察
Object.keys(result).forEach(key => {
defineReactive(vm, key, result[key]); // 设置为响应式
});
toggleObserving(true); // 恢复深度响应式观察也就是说,通过props或者inject接收的数据,最终都会代理到vm上方便访问,且都会变成响应式(一个浅层一个深层)
后续变化不同
- 通过props传递的即便是一个基本数据类型,在父组件中修改了,子组件视图也会更新;因为会调用父组件的render方法,创建新的组件VNode,然后再
patchVNode阶段,更新组件实例的_props,由于_props是响应式的,所以能触发子组件视图更新。 - 但是如果通过provide传递一个基本数据类型,在父组件中修改了,子组件视图也不会更新,因为父组件不会重新provide值,子组件也不会重新inject,provide和inject都是一次性的。
Vuex
关于vuex的介绍,详见vue | 三叶的博客
谈谈对el和template属性的理解
当我们在学习Vue的基础语法,vue的组件的时候一定涉及到了这两个容易混淆的属性。
创建Vue根实例必须要给出el属性,指明要为哪个容器服务,这个容器会成为模板;创建组件实例不能传入el属性,简单的来说,el属性是Vue根实例独有的。
虽然el属性是vue根实例独有的,但它也不是什么优先级很高的东西,如果创建vue根实例同时配置了el和template属性,则template将替换el指定的容器(拜拜了el),成为模板(可以参考
vm.$mount源码,template属性优先级更高)不过要注意的是nodejs开发环境中,通过
import导入的vue是精简版的,没有模板解析器的,模板解析器被单独提取出来,作为一个开发环境的包,只在打包的时候发挥作用,**只用来处理.vue文件中的template**,不会包含到最终文件中,从而减小最终文件的体积。所以在创建vue根实例的时候不能使用template,因为打包后的文件中已经没有模板解析器了,所以无法借助它实现在页面中自动插入<App></App>的效果。1
2
3
4
5
6
7import App from './App.vue'
import Vue from 'vue'
new Vue({
el:'#root',
template:'<App></App>',
components:{App}
})上述代码会报错,不能配置
template应当修改为:
1
2
3
4
5
6import App from './App.vue'
import Vue from 'vue'
new Vue({
el:'#root',
render:h => h(App)//传入的h是createElement函数,用来创建VNode
})或者引入完整版的vue.js
1
import Vue from 'vue/dist/vue.js'
创建组件必须指定组件的结构,即template,组件的模板,不必指定组件为哪个容器服务(不要el)
el指定的容器中的
结构可以被抽离为一个一个单独的模板template,一个个单独的组件,也就是说模板中可以不写实际结构,只写组件标签,这些组件标签会在模板解析的时候被解析。其实组件中的
template也能被拆分,从而形成一个一个组件,这就是组件的嵌套。
说说Vue的生命周期
定义
vue的生命周期指的是vue实例从创建到销毁的过程,可分为vue实例初始化前后,dom挂载前后,数据更新前后,vue实例销毁前后四个阶段。这四个阶段分别对应了8个生命周期函数。生命周期函数指的是在vue实例特定时间段执行的函数。
Vue2中的生命周期函数
- beforeCreate:vue实例刚被创建,能拿到this,部分初始化工作完成,但是数据代理还未开始(未调用
initState方法),此时无法通过this方法data和methods等 - created: 此时几乎所有配置属性比如inject,data,method,computed,props,watch,provide都初始化完成,但是模板解析(是为了得到render函数,render函数是用来创建虚拟dom的)还未开始(未调用
vm.$mount方法),页面展示的是未经vue编译的dom。 - beforeMount:template模板已经解析结束,render函数创建完毕,但是render函数还未调用,还没生成虚拟dom,此时展示的还是旧的页面(未经编译的页面)
- mounted:此时render函数已经被调用,而且虚拟 DOM 已转换为真实 DOM,挂载到页面上,此时对DOM的操作是有效的。
- beforeUpdate:此时数据是新的,页面展示的内容是旧的,因为vue视图是异步更新的,关于异步更新这一点,可以参考后文《说说你对nextTick的理解》
- updated: 此时
新旧虚拟dom比较完毕,页面已更新。 - beforeDestroy:当执行beforeDestroy的钩子的时候,Vue实例就已经从运行阶段进入销毁阶段,但身上所有的data和methods,以及过滤器、指令等,都处于可用状态,还未真正执行销毁的过程
- destroyed: 完全销毁一个实例。可清理它与其它实例的连接,解绑它的全部指令及事件监听器;并不能清除DOM,仅仅销毁实例。所以页面并不会改变,但是变得无法响应交互。
深入理解
数据请求在created和mouted的区别
这两个阶段数据和方法都已经初始化,都能通过this访问到,因为created的执行时期更早,所以能更早的发送请求,更快的返回数据。
对于存在子组件的情况,为什么先执行父组件的created钩子,再执行子组件的created,mounted钩子,最后再执行父组件的mounted钩子
- 在创建父组件实例的时候,调用完
initState,initProvide之后,就会调用父组件的created钩子 - 然后调用
vm.$mount方法,编译父组件的模板,得到父组件的渲染函数,然后创建渲染Watcher,在这个过程就会调用render方法,创建父组件的VNode,父组件的vnode中就包含子组件的VNode,子组件的Vnode中挂载了子组件的构造函数 - 然后调用
patch方法,递归将父组件的VNode转化成真实DOM,并挂载到指定的DOM上;在将子组件vnode转化成真实dom时,会调用子组件的构造函数,开启子组件的构建流程,因此接着调用子组件的created,mounted钩子,将子组件挂载到父组件上。 - 当所有子组件的dom都挂载完毕后,父组件的
mounted钩子才会被触发。
对于vue3中的生命周期的介绍,参考《vue》一文。
说说你对vue双向绑定的理解
双向绑定不等同于响应式了,这两个东西是有区别的。
双向绑定,是数据变化驱动视图更新,视图更新触发数据变化。其实就是v-model的功能,而我们知道v-model只是一个语法糖。因此如果要问双向绑定的原理,思路应该是如何实现这个语法糖。其原理是把input的value绑定data的一个值,当原生input的事件触发时,用事件的值来更新data的值。
1 | <!-- 使用 v-model --> |
说说你对slot的理解?
slot的作用就是用来自定义组件内部的结构
slot可以分来以下三种:
- 默认插槽
- 具名插槽
- 作用域插槽
默认插槽
子组件用<slot>标签,来确定渲染的位置,标签里面可以放DOM结构,当父组件没有往插槽传入内容,标签内DOM结构,就会显示在页面。父组件在使用的时候,直接在子组件的标签内写入内容即可
子组件Child.vue,使用slot标签占位,标签体内的结构是默认结构
1 | <template> |
父组件向子组件传递结构,只需要在子组件标签体内写结构就好了
1 | <Child> |
父组件给子组件传入的自定义结构,可以在子组件的this.$slots属性中拿到。

具名插槽
默认插槽形如
1 | <slot> |
当我们给slot标签添加name属性,默认插槽就变成了具名插槽
当我们需要在子组件内部的多个位置使用插槽的时候,为了把各个插槽区别开,就需要给每个插槽取名。
同时父组件传入自定义结构的时候,也要指明是传递给哪个插槽的,形象的来说,就是子组件挖了多个坑,然后父组件来这些填坑,需要把具体的结构填到具体的哪个坑。
子组件Child.vue
1 | <template> |
父组件
1 | <child> |
template标签是用来分割,包裹自定义结构的。v-slot属性用来指定,这部分结构用来替换哪个插槽,所以v-slot指令是放在template标签上的,要注意的是,如果想要将某部分结构传递给指定的插槽xxx,因该使用v-slot:xxx,而不是v-slot='xxx'
v-slot:default可以简化为#default,v-slot:content可以简化成#content
作用域插槽
子组件在slot标签上绑定属性,来将子组件的信息传给父组件使用,所有绑定的属性(除了name属性),都会被收集成一个对象,被父组件的v-slot属性接收。
子组件Child.vue
1 | <template> |
父组件
1 | <child> |
可以通过解构获取v-slot={user},还可以重命名v-slot="{user: newName}"和定义默认值v-slot="{user = '默认值'}"
所在slot中也存在’’双向数据传递’’,父组件给子组件传递页面结构,子组件给父组件传递子组件的数据。
你有写过自定义指令吗?
什么是指令
在vue中提供了一套为数据驱动视图更为方便的操作,这些操作被称为指令系统。简单的来说,指令系统能够简化dom操作,帮助方便的实现数据驱动视图更新。
我们看到的v-开头的行内属性,都是指令,不同的指令可以完成或实现不同的功能
除了核心功能默认内置的指令 (v-model 和 v-show),Vue 也允许注册自定义指令
指令使用的几种方式:
1 | //会实例化一个指令,但这个指令没有参数 |
注意:指令中传入的都是表达式,无论是不是自定义指令,比如
v-bind:name = 'tom',传入的是tom这个变量的值,而不是tom字符串,除非写成"'tom'",传入的才是字符串。
如何实现
关于自定义指令,我们关心的就是三大方面,自定义指令的定义,自定义指令的注册,自定义指令的使用。
自定义指令的使用方式和内置指令相同,我们不再研究,其中的难点就是定义自定义指令部分。
注册自定义指令
注册一个自定义指令有全局注册与局部注册两种方式
全局注册主要是通过Vue.directive方法进行注册
Vue.directive第一个参数是指令的名字(不需要写上v-前缀),第二个参数可以是对象数据,也可以是一个指令函数
1 | //全局注册一个自定义指令 `v-focus` |
局部注册通过在组件配置对象中设置directives属性
1 | directives: { |
然后就可以使用
1 | <input v-focus /> |
在vue3中,局部注册的语法就不同了。如果混合使用选项式api,就可以像vue2一样借助directives属性解决,如果使用的是setup语法糖写法,就需要遵守如下语法:
1 | <template> |
导入directive函数,传入自定义指令,完成组件的局部注册。
定义自定义指令
自定义指令本质就是一个包含特定钩子函数的js对象
在vue2中,这些常见的钩子函数包括:
bind()
只调用一次,指令第一次绑定到元素时调用。在这里可以进行一次性的初始化设置,此时无法通过el拿到父级元素,也就是el.parentNode为空,但是也已经能拿到绑定的dom元素了。inserted()
绑定指令的元素插入父节点时调用 (仅保证父节点存在,但不一定已被插入文档中,因为父元素可能还没插入文档中呢),此时可以通过
el.parentNode拿到父级元素mounted()
指令绑定的元素被插入到
文档中之后update()
传入指令的值改变后触发
unbind()
只调用一次,指令与元素
解绑时调用
注意:上述钩子函数在vue3中并不都有效,vue3中的自定义指令钩子函数和生命周期函数一致,具体见官方文档,https://cn.vuejs.org/guide/reusability/custom-directives#directive-hooks
所有的钩子函数的参数都有以下:
el:指令所绑定的元素,可以用来直接操作
DOM,省去了手动捕获dom的步骤binding:
一个对象,包含以下property
name:指令名,不包括v-前缀。value:传入指令的表达式的值,例如:v-my-directive="1 + 1"中,绑定值为2。oldValue:指令绑定的前一个值,仅在update和componentUpdated钩子中可用。无论值是否改变都可用。expression:字符串形式的指令表达式。例如v-my-directive="1 + 1"中,表达式为"1 + 1",又比如v-for="(value, key, index) in obj",传入的表达式为"(value, key, index) in obj"arg:传给指令的参数,可选。例如v-my-directive:foo中,参数为"foo",又比如v-bind:class = "['box']"的参数为class,为什么是arg不是args,因为传递给指令的参数只能有一个,而修饰符却可以有多个。modifiers:一个包含修饰符的对象。例如:v-my-directive.foo.bar中,修饰符对象为{ foo: true, bar: true }
vnode:Vue编译生成的虚拟节点oldVnode:上一个虚拟节点,仅在update和componentUpdated钩子中可用
应用场景
给某个元素添加节流
1 | // 1.设置v-throttle自定义指令 |
Vue常用的修饰符
修饰符是什么
在Vue中,修饰符是用来修饰Vue中的指令的,它处理了许多DOM事件的细节,让我们不再需要花大量的时间去处理这些烦恼的事情,而能有更多的精力专注于程序的逻辑处理。
vue中修饰符分为以下五种:
- 表单修饰符
- 事件修饰符
- 鼠标按键修饰符
- 键值修饰符
- v-bind修饰符
修饰符的具体作用
表单修饰符
在我们填写表单的时候用得最多的是input标签,指令用得最多的是v-model
关于表单的修饰符有如下:
- lazy
- trim
- number
lazy
在我们填完信息,光标离开标签的时候,才会将值赋予给value,也就是在change事件之后再进行信息同步
1 | <input type="text" v-model.lazy="value"> |
trim
自动过滤用户输入的首尾空格字符,而中间的空格不会过滤
1 | <input type="text" v-model.trim="value"> |
number
自动将用户的输入值转为数值类型,但如果这个值无法被parseFloat解析,则会返回原来的值
1 | <input v-model.number="age" type="number"> |
事件修饰符
stop:阻止事件冒泡,等在传入的回调函数中添加
event.stopPropagation()1
2
3
4
5
6<button @click.stop="handleClick">点击不会冒泡</button>
//等效于
const handleClickWithStop = (event) => {
event.stopPropagation(); // 手动阻止冒泡
// 其他业务逻辑
};prevent:阻止默认行为,等同于在传入的回调函数中添加
event.preventDefault()1
<form @submit.prevent="handleSubmit">提交表单不会刷新页面</form>
capture:使用事件捕获模式(默认是冒泡模式)
1
<div @click.capture="parentClick">父级先触发</div>
self:仅当事件从元素本身(而非子元素)触发时执行
1
<div @click.self="onlySelfClick">点击子元素不触发</div>
once:事件只触发一次,之后自动移除对该事件的监听,避免因长期持有未使用的监听函数导致内存泄漏、
1
<button @click.once="oneTimeAction">仅首次点击有效</button>
其实在原生dom事件中,实现这个效果也是非常简单的,只需要在第三个参数传入
{ once: true },手动通过removeEventListener还是比较消耗精力的,不过灵活度更大。1
element.addEventListener('click', handler, { once: true });
passive:提升滚动性能,不与
prevent同时使用1
<div @scroll.passive="onScroll">滚动更流畅</div>
当监听
touchstart、touchmove或wheel(滚动)等高频事件时,浏览器的默认行为是:等待事件处理函数执行完毕再决定是否执行默认行为(如滚动页面),如果事件处理函数中存在耗时操作(如复杂计算),会导致 滚动卡顿,因为浏览器必须等待函数执行完毕,才能滚动页面(默认行为)。
passive修饰符的作用,是通过将事件监听器标记为 被动模式(Passive),本质是向浏览器承诺:
“此事件处理函数不会调用event.preventDefault()”,从而允许浏览器 立即触发默认行为,无需等待函数执行。Vue 3 的
.passive修饰符对应原生addEventListener的{ passive: true }配置:1
2// Vue 编译后的等效代码
element.addEventListener('scroll', handler, { passive: true });.passive向浏览器承诺 不会阻止默认行为,而.prevent的作用是 主动阻止默认行为,二者语义冲突,所以不能同时使用。
Vue中组件和插件有什么区别
组件是什么
在vue中,组件就是能实现部分功能的html,css,js代码的集合。
优势
降低整个系统的
耦合度在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,可以替换为日历、时间、范围等组件作具体的实现
提高代码的
可维护性,和可复用性由于每个组件的职责单一,并且组件在系统中是被复用的。
插件是什么
插件通常用来为 Vue 添加全局功能,比如通过全局混入来添加一些组件选项。如vue-router
区别
两者的区别主要表现在以下几个方面:
- 编写形式
- 注册形式
编写形式
组件
编写一个组件,可以有很多方式,我们最常见的就是vue单文件的这种格式,每一个.vue文件我们都可以看成是一个组件。
插件
vue插件就是一个实现了 install 方法的对象。这个方法的第一个参数是 Vue 构造函数,第二个参数是一个可选的选项对象(options)。
1 | MyPlugin.install = function (Vue, options) { |
注册形式
组件注册
vue组件注册主要分为全局注册与局部注册
局注册通过Vue.component方法,第一个参数为组件的名称,第二个参数为传入的配置项
1 | Vue.component('my-component-name', { /* ... */ }) |
局部注册只需在用到的地方通过components属性注册一个组件
1 | const component1 = {...}// 定义一个组件 |
在vue3中的组件注册:
全局注册:
1 | import { createApp } from 'vue'; |
局部注册:
1 | <script> |
或者
1 | <script setup> |
在 <script setup> 中导入的组件会自动注册并在模板中可用,无需显式地在 components 选项中列出它们。
插件注册
插件的注册通过Vue.use()的方式进行注册,第一个参数为插件的名字,第二个参数是可选择的配置项
1 | Vue.use(插件名字[,options]) |
注册插件的时候,需要在调用
new Vue()启动应用之前完成,Vue.use会自动阻止多次注册相同插件,只会注册一次。
v-if和v-for的优先级是什么
在vue2中,v-for的优先级高于v-if,也就是说会遍历所有元素,然后再通过v-if判断是否是要渲染,即使某些项最终不满足 v-if 条件,v-for 仍会遍历这些项。
1 | <ul> |
而在vue3中,v-if的优先级高于v-for,所以在vue3中,上述代码会报错,会提示item未被定义;
这也意味着在vue3中,无法根据某个对象的属性,使用v-if来控制渲染。
其实最推荐的做法是只迭代并渲染需要渲染的数据,不在同一个元素上使用v-if和v-for,这就需要我们提前过滤元素。
v-if和v-show如何理解
共同点
二者都是用来控制页面中元素的显示与隐藏,当表达式值为false的时候,都不会占据页面的位置。
区别
v-show本质是通过切换css样式来实现元素的显示与隐藏,令display:none让元素隐藏,dom元素还存在。
v-if本质则是通过控制dom元素的创建与删除来实现元素的显示与隐藏,因为v-if直接操作dom,所以v-if有更高的性能消耗。
v-if才是真正的条件渲染,v-show的值为false的元素,也会被渲染,因为它还是会出现在文档中,只是变得不可见且不占据位置。
说说你对nextTick的理解
在vue中,虽然是数据驱动视图更新,但是数据改变(同步改变),vue异步操作dom来更新视图;而传入nextTick的回调函数,能确保在DOM更新之后再被执行,所以nextTick回调函数中能访问到最新的DOM。
使用方法
Vue.nextTick(()=>{})或者this.$nextTick(()=>{}),二者的区别在于后者的回调函数中会自动绑定组件实例。
1 | <div id="app"> {{ message }} </div> |
1 | //使用回调函数 |
如果调用nextTick的时候,没有传入回调函数,则会返回一个Promise对象,当这个Promise对象的值改变后,就能访问到最新的DOM
1 | //使用async/await |
底层实现
1 | const callbacks = [] // 存放传入nextTick的回调函数 |
callbacks新增回调函数后,又执行了timerFunc函数,那么这个timerFunc函数是做什么用的呢,我们继续来看代码:
1 | export let isUsingMicroTask = false //判断是否使用的是微任务 |
上述代码描述了timerFunc的是如何被定义的,做了四个判断,对当前环境进行不断的降级处理,尝试使用原生的Promise.then、MutationObserver和setImmediate,上述三个都不支持最后使用setTimeout。前两者将清空callbacks的任务放入微任务队列,后两者将清空callbacks的任务放入宏任务队列
通过四个判断可以确保,无论在何种浏览器条件下,都能定义出最合适timerFunc。而且四种情况下定义的timerFunc,效果都是,将flushCallbacks放入微任务(或者宏任务)队列。
timerFunc不顾一切的要把flushCallbacks放入微任务或者宏任务中去执行,它究竟是何方神圣呢?让我们来一睹它的真容:
1 | function flushCallbacks () { |
来以为有多复杂的flushCallbacks,居然不过短短的几行。它所做的事情也非常的简单:
- 把callbacks数组复制一份,然后把
callbacks置为空 - 最后把复制出来的数组中的每个函数依次执行一遍;
- 所以它的作用仅仅是用来执行callbacks中的所有回调函数,也就是说,callbacks中的任务,会在微任务阶段(或者宏任务)被执行。
如何确保此时DOM是最新的?
经过上面的介绍我们知道,传入nextTick的回调函数,通常会在微任务阶段被依次执行,那又是如何确保nextTick中的回调函数访问到的DOM是最新的DOM呢?
更新dom的回调函数,也是通过nextTick添加到任务队列中的
上面这段话如何理解?我们知道,状态改变了,通常会通知模板更新,也就是会调用渲染Watcher的update方法,我们先看看Watcher的update方法:
1 | update () { |
由此可知,渲染watcher更新会走queueWatcher(this)的逻辑,那queueWatcher(this)到底做了什么?
1 | const queue = [] |
分析上述代码可知,调用渲染Watcher的update方法,会将渲染Watcher放入一个异步更新队列,然后清空这个异步更新队列的任务(),会被放入nextTick的callbacks中,而callbacks中还存储了我们调用nextTick传入的回调,callbacks中的回调函数,通常会在微任务阶段依次执行。
什么是虚拟DOM吗,有什么作用?
操作真实dom
这部分内容主要参考js中的事件循环,可参考本博客内的《javascript》一文
在原生 JavaScript 的事件循环中,多次 DOM 操作会 立即修改内存中的 DOM 树,但浏览器通过 批量更新,合并机制, 延迟视图渲染至事件循环末尾。
1 | // 同一事件循环中多次修改同一元素的样式 |
浏览器会将这三次样式修改,合并为一次渲染流程,而非逐次触发三次重排,所以不会看到样式闪烁,因为只渲染了一次。
虽然减少了渲染次数,但每次 DOM 操作仍会 立即修改内存中的 DOM 树,频繁操作可能导致主线程阻塞(如复杂布局计算),因为操作真实DOM是费时的(比如一个DOM对象身上有很多属性,创建一个DOM是费时间的),所以在Vue等框架中,使用虚拟DOM和diff算法,来减少操作真实DOM的次数。
虚拟DOM
虚拟DOM,也叫虚拟DOM树,本质就是一个用来描述真实DOM树的js对象,是对真实DOM树的高度抽象。
1 | <div id="app"> |
将上面的HTML模版抽象成虚拟DOM树:
1 | { |
操作虚拟 DOM 的速度,比直接操作真实 DOM 快 10-100 倍。
VNode
虚拟DOM树本身是一个js对象,是对真实DOM树的高度抽象;而VNode是虚拟DOM树上的结点,是对真实DOM结点的抽象,它描述了应该怎样去创建真实的DOM结点。
在vue中,VNode其实就是就是一个VNode类创造出来的实例,这个vnode上有许多属性比如key,text,tag,elm,isComment,children等。
vnode有很多种类型,比如注释结点,文本结点,元素结点,组件结点,函数式组件和克隆结点。
其中注释结点只有2个有效属性text和isComment,其余属性全是默认的undefined或者null。文本结点只有一个text属性。
克隆结点和被克隆结点上的属性几乎完全一样,唯一的区别是克隆结点的isCloned属性为true,而被克隆结点的这个属性为false。
元素结点通常存在四个有效属性:
- tag:结点的名称,比如div,p,li
- data:包含了结点上的数据,比如class和style
- children:当前结点的子节点列表,是一个vnode数组
- context:当前组件的vue.js实例
组件结点的有效属性包括:
- componentOptions:组件的配置对象
- componentInstance:组件的实例
- context:父组件的vue.js实例
- data:组件标签上的一些属性
- tag:组件标签名,特征是以
vue-component开头
将vnode转化成dom,挂载到哪儿?
VNode 转化为真实 DOM 后,会被插入到其父 VNode 对应的真实 DOM 元素(
parentElm)中,并且通常插入在参考节点(refElm)之前。如果是根组件,最终会挂载到你调用
$mount(el)时指定的容器上。
举例说明:
1 | new Vue({ |
生成的vnode:
1 | vnode = { |
调用 vm.$mount() → 触发 __patch__
1 | vm.$el = vm.__patch__(vm.$el, vnode) |
oldVnode 为vm.$el(挂载点,旧的dom,会转化成oldVnode),vnode 是新的根vnode,在__patch__ 内部会调用 createElm(vnode, insertedVnodeQueue, parentElm, refElm),根据vnode创建新的dom。
- vnode:当前要创建的 VNode
- insertedVnodeQueue: 待插入的组件队列(用于触发钩子)
- parentElm 父元素的真实 DOM 节点,在这个例子中等于
vm.$el.parentNode - refElm参考节点(插入位置的锚点)、
传入的parentElm = document.getElementById('app')
1 | function createElm(vnode, insertedVnodeQueue, parentElm, refElm) { |
在Vue中的情况
在vue中,虽然是数据驱动视图更新的,当数据被修改时,会触发对应的 setter,但不会立即修改dom,而是通知依赖更新,调用所有依赖(Watcher)的update方法:将Watcher自身放入异步更新队列中。
然后在微任务阶段,清空异步更新队列:
调用每个Watcher的
run方法,要注意的是,虽然每个Key都可以有多个Watcher,但并不是所有Watcher都是渲染Watcher(负责组件的视图更新,每个组件对应一个渲染 Watcher),只有渲染 Watcher 的run方法触发render,生成新虚拟 DOM → Diff → DOM 更新。如果完全按照新的虚拟dom树,来创建新的dom树,就会有许多不必要的dom操作,所以我们会使用diff算法,进行新旧虚拟DOM树的比较,得出最小的变更,应用到对真实dom树的修改。
综上所述,在vue中对真实DOM的修改,是在微任务阶段发生的,然后就到了事件循环的末尾,因为对DOM进行了修改,所以会进行一次渲染。
如何diff新旧虚拟DOM树
diff算法
在vue中,我们使用diff算法来进行新旧虚拟dom树的比较。diff 算法是一种在同层的树节点,进行比较的高效算法
特点:
- 从根结点开始比较,然后再对比子节点
- 比较只会在同层级进行, 不会跨层级比较
- 在比较子节点的过程中,从两边向中间循环比较
简化后的虚拟节点(vnode)大致包含以下属性:
1 | { |
文本结点的tag为undefined,children也是空数组,text的值是文本内容
diff新旧虚拟DOM树,本质就是比较两棵树的区别,很显然我们需要先从两棵树的根结点开始对比,。
patch
在组件的一次模板更新中,patch方法只会被调用一次,传入的是整个组件的vnode和oldVnode
1 | //简化后的patch |
1 | function sameVnode (a, b) { |
调用
patch方法,传入新旧虚拟结点(oldVnode, vnode)没有新节点:vnode = undefined,说明旧的结点该被删除了,直接触发旧节点的
destory钩子,移除旧的dom;没有旧节点:oldVnode = undefined,说明是页面刚开始初始化的时候,此时,根本不需要比较了。直接使用新的vnode来创建dom,所以要只调用
createElm,将新的vnode转化成真实dom。如果oldVnode, vnode都存在,则调用
sameVNode方法,从key,tag等方面判断是否属于同一结点,如果返回true,表明结点可复用,则进一步调用patchVNode方法,给dom打补丁;如果
sameVNode返回false,说明旧的dom不可复用,直接使用新的vnode创建新的dom,插入到旧的dom旁边(左边或者右边),然后移除旧的dom。
patchVNode
patchVnode方法中执行的是真正的更新操作
1 | function patchVnode (oldVnode, vnode) { |
进一步比较oldVnode, vnode,如果oldVnode === vnode,也就是说新旧虚拟结点完全相同,则直接return,什么也不做。
如果新旧虚拟结点不同,则让vnode引用oldVnode的dom。
先对dom的属性打补丁:对属性打补丁其实就是调用各种updateXXX()函数,更新真实dom的各个属性,确保dom属性和vnode属性一致。
再对子元素打补丁:
如果vnode和oldVnode都是元素结点:
- 如果都有子元素,则调用
updateChildren方法对比更新子元素,这涉及到diff算法的核心部分。 - 如果vnode有子节点,而oldVnode没有,那么不用比较了,直接新建全部子节点,插入父节点中。
- 如果oldVnode有子节点,而vnode没有,说明更新后的页面,子节点全部都不见了,那么要做的,就是把所有旧的子节点删除(也就是直接把
DOM删除)。
如果vnode和oldVnode都是文本或者注释结点:则用vnode的文本更新旧dom的文本
对于给属性打补丁,每个的update函数都类似,拿updateAttrs()举例看看:
1 | function updateAttrs (oldVnode, vnode) { |
总结一下上述代码主要流程:
遍历vnode(新的vnode)属性,如果和oldVnode不一样,就调用
setAttribute()修改;遍历oldVnode属性,如果不在vnode属性中,就调用
removeAttribute()删除确保新的dom属性和vnode属性相同
updateChildren
暴力搜索法
从左到右遍历newChildren中的vnode,对于每个vnode:
- 如果在oldChildren中找不到相同的oldVnode,则创建新的dom,插入到所有未更新的dom前
- 如果在oldChildren中找到了相同的oldVnode,且位置相同,则只需要执行patchVnode;
- 如果在oldChildren中找到了相同的oldVnode,但是位置不同,还需要将dom插入到所有未更新的dom前,然后再执行patchNode。
优化策略
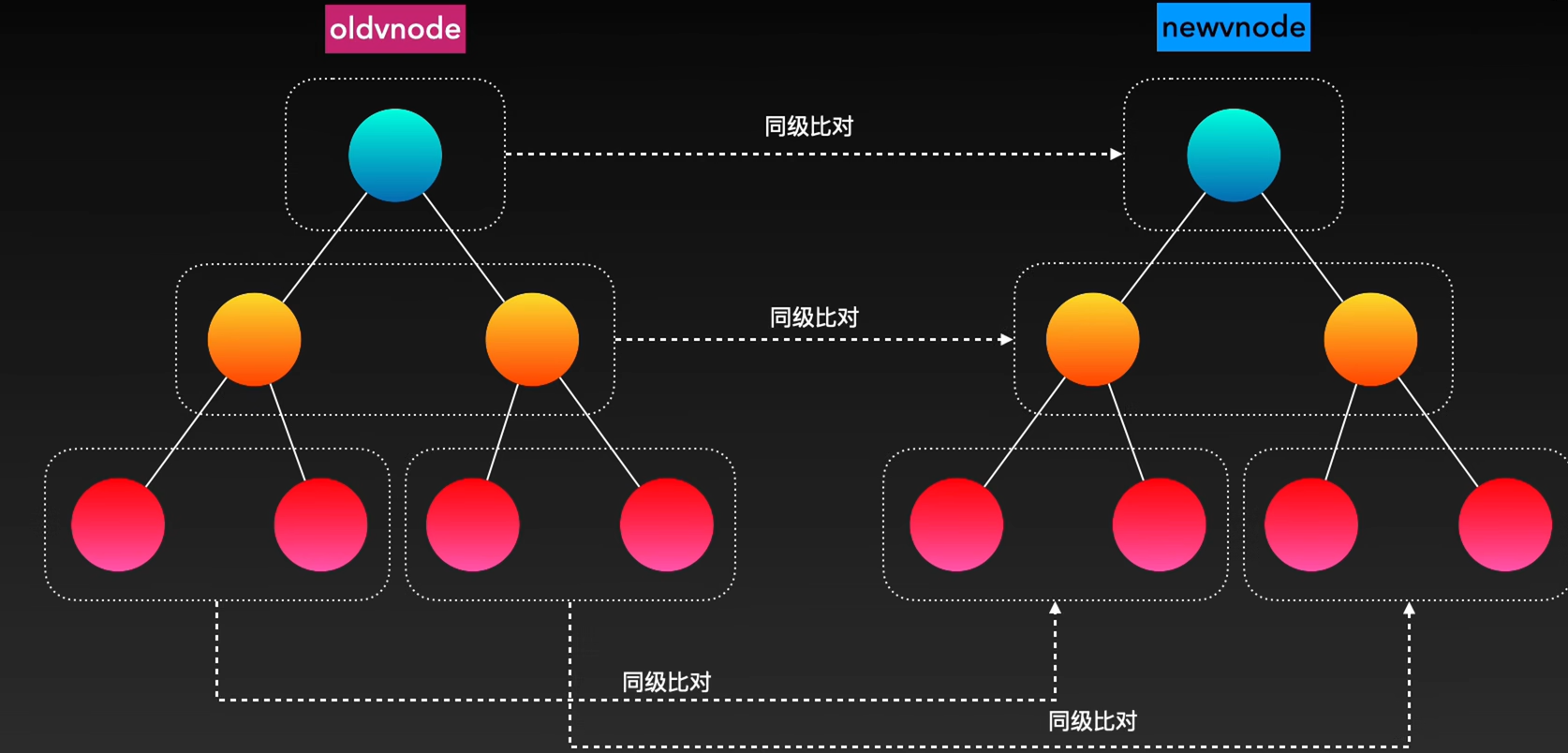
首尾指针法:给newChildren和oldChildren,都添加首尾指针
- 检查newChildren中头指针指向的vnode和oldChildren中头指针指向的vnode,是否相同,如果相同,只需进行patchVNode然后将2个头指针右移。
- 如果不同,再检查newChildren中尾指针指向的vnode和oldChildren中尾指针指向的vnode,是否相同,如果相同,只需进行pathVnode然后将2个尾指针向左移动。
- 如果不同,再检查newChildren中尾指针指向的vnode和oldChildren中头指针指向的vnode,是否相同,如果相同,在patchVnode之后,将对应的dom结点移动到所有未处理的dom结点后面
- 如果不同,再检查newChildren中头指针指向的vnode和oldChildren中尾指针指向的vnode,是否相同,如果相同,在patchVnode之后,将对应的dom结点移动到所有未处理的dom结点前面
- 如果通过头头,尾尾,尾头,头尾的检查,都没有找到相同的vnode,则使用循环的方式逐个匹配。
- 当任意一个头指针大于它的尾指针,退出循环
- 循环结束时,删除/添加多余dom
1 | function updateChildren (parentElm, oldCh, newCh) {//传入的参数是新旧虚拟子节点数组 |
总结
参考资料:
- 面试官:你了解vue的diff算法吗?说说看 | web前端面试 - 面试官系列
- javascript - Vue源码解析:虚拟dom比较原理 - 个人文章 - SegmentFault 思否
- 6分钟彻底掌握vue的diff算法,前端面试不再怕!_哔哩哔哩_bilibili
案例
1 | <div class="parent"> |
当我们修改子元素的内部文本:
1 | <div class="father"> |
调用patch方法,传入vnode和oldVnode,二者显然属于sameVnode(tag未改变,都没有key),所以进行patchVnode;显然vnode和oldVnode不是完全相同的,所以让vnode引用oldVnode的dom,也就是dom复用;然后根据vnode更新dom的属性;由于vnode和oldVnode都是元素结点且独有子元素,所以调用updateChild方法,显然新旧2个子元素属于sameVnode,且位置相同不需要移动dom,直接进行patchVnode,依次类推,最终执行的是文本结点内容的更新。
说说你对vue中key的理解
key是给每一个vnode的唯一id,是sameVnode方法的重要判断依据,在diff过程中,根据key值,可以更准确的找到匹配的新旧vnode,从而优化diff算法,提高dom的复用率。如果不设置key,那key值默认就都是undefined,只要tag相同,就会被认为是相同的vnode。
详细可参考禹神的vue视频:030_尚硅谷Vue技术_key作用与原理_哔哩哔哩_bilibili
说说你对keep-alive的理解
keep-alive是vue中的内置组件,包裹动态组件(router-view)时,会缓存不活动的组件实例,而不是销毁它们,防止重复渲染DOM。
被缓存的组件会额外多出两个生命周期activated和deactivated
keep-alive可以使用一些属性,来更精细的控制组件缓存。
include- 字符串或正则表达式或者一个数组。只有名称匹配的组件会被缓存exclude- 字符串或正则表达式或者一个数组。任何名称匹配的组件都不会被缓存max- 数字:最多可以缓存多少个组件实例,超出这个数字之后,则删除第一个被缓存的组件,由此可以推测存在一个缓存队列,先入先出。
1 | <keep-alive include="a,b"> |
组件名称匹配,组件名称指的到底是什么呢?
匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值),匿名组件不能被匹配。
组件被缓存了,如何获取数据呢?
借助beforeRouteEnter这个组件内的导航守卫,或者activated生命周期函数
1 | beforeRouteEnter(to, from, next){ |
1 | activated(){ |
面试官:说说你对keep-alive的理解是什么? | web前端面试 - 面试官系列这篇文章中还讲解了keep-alive的实现原理,看起来还是挺复杂的
vue3中的keep-alive的语法不同于vue2
基础用法,默认缓存所有页面:
1 | <router-view v-slot="{ Component }"> |
- Component可以理解为用来替代router-view的组件,或者说当前活跃的组件
- keep-alive包裹的不再是router-view而是具体的组件
精确控制具体哪些组件缓存,因为再vue3中使用组件已经不再需要注册,也不需要给组件命名,所以我们控制组件(页面)缓存的依据变成了页面的路由对象,而不是组件的名称。同时,我们不再通过给keep-alive标签添加属性,来控制哪些组件该被缓存,缓存多少组件,转变为借助v-if,如果某个组件因该被缓存,那么他就会被keep-alive标签包裹。
1 | <template> |
在路由对象中添加meta属性
1 | { |
或者
1 | <router-view v-slot="{ Component, route }"> |
但是就到此位置的话,切换页面的时候会报错:vue3 TypeError: parentComponent.ctx.deactivate is not a function 报错
网上提供的解决方案就是给每个component提供一个key。
1 | <router-view v-slot="{ Component, route }"> |
详细可参考:vue3中使用keep-alive目的:掘金
SPA
什么是SPA,和MPA有什么区别?
SPA指的是只有一个页面的web应用程序,所有必要的代码(
HTML、JavaScript和CSS)都通过单个页面的加载而被加载(这样首屏加载速度就很慢),或者根据需要(通常是为响应用户操作),动态装载适当的资源,并添加到页面,页面在任何时间点都不会重新加载,也不会将控制转移到其他页面。MPA(多页面应用程序)指的是有多个页面的web应用程序
SPA通过js操作dom,来局部更新页面内容;而MPA是通过页面切换,来实现整页的刷新,整页刷新就需加载整个页面所有
资源,并重新渲染页面,速度慢;SPA刷新速度更快,用户体验更好,同时把页面渲染工作交给客户端,减轻了服务端的压力。
缺点是不利于搜索引擎优化(SEO),首屏加载速度较慢,当然这些问题都是可以解决的。
面试官:你对SPA单页面的理解,它的优缺点分别是什么?如何实现SPA应用呢 | web前端面试 - 面试官系列
如何实现SPA
SPA是通过hash路由或者history路由实现的,问如何实现SPA,其实就是在询问这两种路由是如何实现,关于这一点,可以参考后文。
如何提高首屏加载速度?
首屏加载时间,指的是浏览器从响应用户输入网址,到首屏内容渲染完成的时间,此时整个网页不一定要全部渲染完成,但需要展示当前视窗需要的内容。
首屏加载慢的原因
- 网络延时问题
- 资源文件体积是否过大
- 资源是否重复发送请求去加载了
- 加载脚本的时候,渲染内容堵塞了
使用路由懒加载
使用路由懒加载能减少资源的加载时间,确保只加载首屏需要的资源
- 对于非首屏组件,使用路由懒加载,当需要访问这些组件的时候,再加载对应的资源。路由懒加载本质就是异步加载js,css文件,或者说按需加载js,css文件。
- 开发单页面应用程序时,只有一个
html页面,打包后也只有一个index.html页面,其他所谓的页面,都是通过JavaScript动态地修改DOM来实现的。 - 开发过程中,一个页面对应一个或者多个
组件,在打包后,每个组件都会转化成对应的css,js代码,其中的js代码不光包括业务逻辑,也负责修改dom,构建页面。 - 如果使用
路由懒加载,我们可以观察到,打包后的js,css文件数量变多了,每个文件的体积也变小了。 - 这是动态导入import触发的代码分割,Webpack / Vite 等构建工具,会将每个懒加载的组件打包成一个独立的 chunk(代码块)。这样,
index.html引入的主包体积也会变小(js,css文件)
关于路由懒加载的介绍可参考:Vue Webpack 打包优化——路由懒加载(按需加载)原理讲解及使用方法说明- 掘金
所以使用路由懒加载就一定比不使用懒加载好吗,对哪些组件使用懒加载比较好?
访问使用了路由懒加载的组件,需要发送额外的请求获取js和css文件,对于非首屏、访问频率低的路由组件,使用懒加载是推荐的;
推荐使用懒加载的组件:
| 场景 | 原因 |
|---|---|
| 非首屏路由组件(如:用户中心、设置页、帮助文档) | 减少首屏加载体积,提升首屏渲染速度(LCP) |
| 大体积组件(如:富文本编辑器、数据看板、图表页) | 避免一次性加载大量 JS/CSS,阻塞主线程 |
| 低频访问页面(如:隐私政策、关于页面) | 用户可能根本不会访问,没必要预加载 |
| 按角色权限隔离的页面(如:管理员后台) | 非管理员用户无需加载相关代码 |
不推荐使用懒加载的组件:
| 场景 | 原因 |
|---|---|
| 首屏必现的路由组件(如:首页、登录页) | 懒加载会导致额外网络请求,延迟渲染,反而变慢 |
| 用户几乎肯定会访问的页面(如:商品详情页) | 预加载比懒加载更高效,避免运行时加载延迟 |
| 组件体积非常小(如:几个 KB 的简单页面) | 分割 chunk 的 HTTP 开销可能大于收益 |
缓存静态资源
使用缓存能直接避免加载资源,直接使用缓存中的资源
对于已经请求过的资源,再次请求直接使用缓存。比如我们每天都要刷b站,可以观察到,B站的页面样式改变的频率是比较低的,如果我们每次登录b站,都要重新请求这些css样式文件,然后再解析渲染,就比较慢了,但是如果我们缓存这些css文件,下次就可以省去加载这些资源的时间,从而提高首屏加载速度。再比如,对于首屏固定不变的图片,如果我们缓存了,下次也可以直接使用。
给script标签添加defer或者async属性
给script标签添加defer或者async属性,能让加载js文件的时候,不阻塞dom树的构建
压缩等js,css,html等静态资源的大小
压缩静态资源的大小能减少资源的加载时间
这一点是显而易见的,压缩静态资源的大小,我们加载这些资源的时间就变少了,从而提高了首屏加载速度。我在部署自己的博客前,也会先把将要上传的图片,样式表,js文件,html文件等静态资源统一压缩,再上传,以求提高首屏加载速度。在实际开发过程中,这个功能通常是由webpack等模块化打包工具自动实现的。
内联首屏关键js,css
内联首屏关键css或者js文件,这样首屏关键css和js就会随着html文件的下载而被下载,不但能减少请求的次数,还能提高首屏的渲染速度。关键是如何内联?
从http请求优化
减少http请求的次数,能缩短资源的加载时间
- 将多个体积较小的css或者js文件,合并为单个文件(如
bundle.css),减少请求次数。 - 使用雪碧图(或者说精灵图),减少请求小图片的次数
使用服务端渲染SSR
使用服务端渲染,可以省去前端拼接html结构的工作
将首页的html结构的拼接工作,交给后端服务器,关于服务端渲染的介绍参考后文。
对于vue,推荐使用nuxt.js,但是我现在还不会。
如何提高SPA的SEO
首先我们思考一个问题,为什么需要提高SPA的seo?
- 传统web开发,一般就是多页面应用程序,每个页面的html结构都在服务端拼接好,所以没有SEO问题。
- SPA的页面内容通过 Js 动态渲染,初始 HTML 通常是空壳(如
<div id="root"></div>),真实内容由 JS 后续填充。 - 传统搜索引擎爬虫(如早期 Googlebot)可能无法执行 JavaScript,导致只能抓取空白页面。
那如何解决SPA的SEO问题呢?答案是使用服务端渲染
服务端渲染(SSR),指由服务端完成页面的 HTML结构拼接的页面处理技术,发送到浏览器,然后为其绑定状态与事件,成为完全可交互页面的过程。使用服务端渲染,返回的页面,就已经包含了一定的页面结构,能够被搜索引擎爬虫爬取
除了能提高SPA的SEO,使用服务端渲染还能提高首屏的加载速度,因为不需要浏览器执行js来拼接html。
简单实现的代码如下:
1 |
|
1 | //因为是在服务端运行的代码,所以使用的是cjs语法 |
hash路由和history路由的实现原理,二者有什么区别?
哈希路由(Hash-based Routing)和 History 路由(History API-based Routing)是前端路由的两种常见实现方式,它们用于在单页面应用程序 (SPA) 中模拟多页面体验,而无需重新加载整个页面。
hash路由
是什么
前端路由被放到url的hash部分,即url中#后面的部分。哈希值改变也不会触发页面重新加载,但是会产生历史记录。- 浏览器不会将
哈希值发送到服务器,因此无论哈希值如何变化,刷新页面,服务器只会返回同一个初始 HTML 文件。
优缺点
- 不需要服务器配置支持,因为哈希值不会被发送给服务器。
兼容性好,几乎所有浏览器都支持哈希变化事件。- URL 中包含显眼的
#符号,可能影响美观。 - 前端路由部分十分明确,方便部署,可以部署在服务器的
任何位置。
如何做
可以直接设置 window.location.hash 属性来改变 URL 中的哈希部分,改变 window.location.hash 不会触发页面刷新,但它会添加一个新的历史记录条目。
前端 JavaScript 监听 hashchange 事件来检测哈希的变化,并根据新的哈希值更新页面内容。
1 | class Router { |
history路由
是什么
使用标准的路径形式,例如 http://example.com/page1,前端路由被放到url中的资源路径部分
优缺点
没有显眼的
#号,更为美观非常适合用来做服务端渲染,从而提高页面的SEO
- 使用History 路由的项目,前端路由混合在url的资源路径部分
- 这意味着前端路由能发送到后端服务器,后端服务器能为每一个前端路由生成对应的完整的html文件。
- 使用了ssr的History 路由项目,搜索引擎爬取每一个前端页面都能得到完整的html结构,从而提高了项目的seo。
需要后端支持,否则会出现
404问题,因为前端路由会被当作资源路径,发送到后端,而后端并未做对应配置。对较老版本的浏览器兼容性较差,因为history路由是基于在H5才提出的History API
要求
index.html文件引用资源的路径,必须使用绝对路径因为基于History API,我们可以改变URL但是不实现页面跳转,展示的始终是同一个index.html文件。
但是当我们改变路由后(比如从
http://localhost:3000变成http://localhost:3000/it/about),再手动刷新页面的时候,就会发送get请求http://localhost:3000/it/about到服务器(假设是开发服务器devServer),显然对于这个请求url,开发服务器找不到对应的资源,于是返回根目录(通常是public文件)下的
index.html文件(歪打正着)但是其他资源就没有这么好运了,浏览器拿到这个页面进行解析渲染,然后加载页面中的资源,比如css文件,如果我们使用的是相对路径,最终请求这些资源的请求路径,还会与当前页面url拼接,所以当前页面的url是不确定的,而我们资源的位置肯定是固定的,所以很容易找不到对应的资源,所以开发服务器返回
index.html文件,你没看错,我们请求css文件结果服务端返回了html文件,然后浏览器就报错了。
history路由的项目一般部署在
服务器根目录,域名后面的路径就是前端路径,否则需要在前端路由库(比如VueRouter)中做额外配置,确保浏览器能从url中提取出前端路径。1
2
3
4
5
6
7const router = new VueRouter({
mode: 'history',
base: '/app/', // 设置基础路径
routes: [
// 你的路由配置
]
});例如,如果用户的 URL 是
http://example.com/app/user/profile,那么前端路由库会将/user/profile视为实际的路由路径,而/app/则被视为基础路径。
如何做

使用 HTML5 的 History API (history.pushState() 和 history.replaceState()) 来修改 URL,而不会触发页面刷新。
要注意的是,调用这2个api都不会触发popstate事件,只有在用户导航历史栈(通过浏览器的后退或前进按钮)时,才会触发 popstate 事件;而hashchange事件,无论是通过js修改hash,还是点击前进后退按钮修改hash,都会触发hashchange事件
history.pushState(state, title, url)
功能:
向浏览器的
历史栈中添加一个新的记录,历史栈长度+1,并更新
当前 URL,但不重新加载页面。
参数
state: 一个对象,用于存储与该状态相关联的数据,可以通过popstate事件的事件对象event访问。1
2
3
4window.addEventListener('popstate', e => {
//console.log(e)
const path = e.state && e.state.path;
});也可以通过
history.state属性访问。title:通常被忽略或设为空字符串(大多数浏览器不支持)。url:新的 URL,可以是相对路径或绝对路径,但不能改变域名,否则会报错。
history.replaceState(state, title, url)
- 功能:
- 替换当前的历史记录条目,而不是添加新的条目。
- 它同样更新
当前 URL但不刷新页面。
- 参数:与
pushState相同。
监听 popstate 事件来响应浏览器的前进/后退按钮操作。
最终代码实现:
1 | class Router { |
vue如何做前端性能优化
前端性能优化就包括了《如何提高首屏的加载速度》。
编码优化
- 使用事件代理:使用事件委托能减少内存占用,减少不必要的重复代码。关于事件委托的介绍,可以参考前端面试—js部分 | 三叶的博客,但是其实需要用到事件代理的场景不多
- 使用
keep-alive缓存组件:会缓存不活动的组件实例,而不是销毁它们,防止重复渲染DOM。关键是keep-alive的原理是什么? - 使用路由懒加载,本质是按需加载css,js文件
- 保证key值唯一,有利于diff算法复用dom,虽然key值不唯一也会提示,也不需要我们操心,关键是diff算法的步骤是什么?
减少资源体积
这部分的内容,其实主要是模块化打包工具帮助我们实现的,不需要我们操心。
- 压缩css,js文件:使用打包工具比如webpack,vite压缩css,js文件。问题是打包工具是如何压缩文件的?比如,删除注释,空格,合并多个文件
tree-shaking:使用tree-shaking移除未使用的代码,减少最终打包后的文件体积,虽然现在的打包工具都默认支持tree-shaking。- 压缩图片体积:使用webp格式替代jpg或者png格式的图片,压缩图片体积。
加载优化
- 使用图片懒加载,我们可以手动实现图片懒加载指令
- 缓存图片,css,js文件等静态资源。在构建过程中,为静态资源文件名添加内容哈希值(例如
app.a1b2c3d4.js),这样每次更新文件时都会生成一个新的URL,浏览器会认为这是一个全新的资源而重新下载它,而不是使用缓存,这是也是打包工具会帮忙做的事情。
http请求优化
减少http请求的次数
- 将多个体积较小的css或者js文件,合并为单个文件(如
bundle.css),减少请求次数。 - 使用雪碧图(或者说精灵图),减少请求小图片的次数
- 内联首屏关键css或者js文件,这样首屏关键css和js就会随着html文件的下载而被下载,不但能减少请求的次数,还能提高首屏的渲染速度。关键是如何内联?
原理
- 每个请求和响应都包含头部信息,虽然这些头部信息通常很小,但在大量小文件的情况下,累积起来也会影响性能。
- 浏览器对同一域名下的并发请求数有限制(通常是6个),这意味着如果同时有超过这个数量的请求,则需要排队等待,进一步增加了加载时间。
Vue项目中你是如何解决跨域的呢?
是什么
跨域本质是浏览器基于同源策略的一种安全手段,它是浏览器最核心也最基本的安全功能,服务器间通信不会有跨域的问题。
所谓同源(即指在同一个域)具有以下三个相同点
- 协议相同(protocol)
- 主机相同(host)
- 端口相同(port)
反之非同源请求,也就是协议、端口、主机其中一项不相同的时候,这时候就会产生跨域(非同源产生跨域)
举个例子,我们直接打开 HTML 文件使用的是file:///协议加载,如果文档内部请求了其他网络资源,因为HTTP 请求使用的是 http:// 或 https:// 协议,协议不同,就发生了跨域。
和跨站有什么区别呢?跨站不涉及协议和端口号,一般情况下,跨站指的就是主域名不同,比如www.bilibili.com和game.bilibili.com属于同站。
如何解决
- JSONP
- CORS
- Proxy
JSONP
利用了
script标签可以跨域加载脚本动态创建一个script标签,并自定它的src属性为目标服务器的url
这个url通常包含一个查询参数,用于指定客户端上的回调函数名
服务端接收到请求后,返回包含函数调用的js代码,其中传入函数的参数,就是服务器传递的参数。
但jsonp请求有个明显的缺点:只能发送
get请求
1 | function onClick(){ |
1 | <button onclick="onClick()">+</button> |
其实还有其他标签可以跨域加载资源,貌似大部分标签都可以跨域加载资源…
媒体资源
| 标签 | 作用 |
|---|---|
| img标签 | 可以跨域加载图像资源,但是如果给img标签加上crossorigin属性,那么就会以跨域的方式请求图片资源 |
| audio和video标签 | 可以跨域加载视频,音频 |
前端基础三大文件
| 标签 | 作用 |
|---|---|
| link标签 | 可以跨域加载CSS文件 |
| iframe标签 | 可以跨域加载HTML页面。 |
| script标签 | 可以跨域加载脚本 |
crossorigin属性
虽然上述三大标签默认可以跨域加载资源,但是如果添加了crossorigin属性,情况就不同了,此时加载资源同样受同源策略限制,请求这这些资源的时候,会携带Origin头,并且要求响应头中包含Access-Control-Allow-Origin字段。
尽管 <script> 默认允许跨域加载,但 crossorigin 属性的核心意义在于:
调试需求:前端可以获取跨域脚本的详细错误日志(开发阶段尤其关键)
安全增强:强制验证服务器是否明确允许当前来源(避免滥用第三方资源)。
特殊资源要求,例如:
字体文件:通过
<link>加载的跨域字体必须使用crossorigin。ES6 模块:
<script type="module">加载的模块必须启用 CORS,所以说vue3项目打包后,引入js文件的方式如下:1
<script type="module" crossorigin src="/assets/index-RPTkaswq.js"></script>
默认添加了
crossorigin头。
| 行为 | 不加 crossorigin | 加 crossorigin |
|---|---|---|
| 是否允许跨域加载 | ✅ 允许 | ✅ 允许(需服务器支持 CORS) |
| 是否验证 CORS 头 | ❌ 不验证 | ✅ 必须验证 |
| 错误信息详情 | ❌ 仅 Script error.跨域脚本可能包含敏感逻辑或数据,因此浏览器不会将详细的错误信息暴露给非同源页面 | ✅ 完整错误信息(需 CORS 允许) |
| 适用场景 | 不关心错误细节的公共库 | 需调试或加载字体/模块等特殊资源 |
Proxy
代理(Proxy)也称网络代理,是一种特殊的网络服务,允许一个(一般为客户端)通过代理与另一个网络终端(一般为服务器)进行非直接的连接。一些网关、路由器等网络设备具备网络代理功能。一般认为代理服务有利于保障网络终端的隐私或安全,防止攻击。
代理的方式也可以有多种:
在脚手架中配置
在开发过程中,我们可以在
脚手架中配置代理。我们可以通过webpack(或者vite)为我们开起一个**本地服务器(**devServer,域名一般是localhost:8080),作为请求的代理服务器,所以说,这个本地服务器不仅能部署我们开发打包的资源,还能起到代理作用。通过该服务器
转发请求至目标服务器,本地代理服务器得到结果再转发给前端,因为服务器之间通信不存在跨域问题,所以能解决跨域问题。打包之后的项目文件,因为脱离了代理服务器,所以说这种方式只能在
开发环境使用。1
2
3
4
5
6
7
8
9
10
11//vue.config.js 即vue-cli脚手架(基于webpack)开发的vue项目
devServer: {
//感觉这些信息都是在告诉代理服务器该怎么做
proxy: {
'/api': {//匹配所有以/api开头的请求路径
target: 'http://localhost:3000', // 告诉代理服务器 请求的目标服务器地址
changeOrigin: true, //告诉代理服务器,请求目标服务器时要修改host(比如localhost:8080->localhost:3000)
pathRewrite: { '^/api': '' }, // 告诉代理服务器,重写路径,移除前缀
}
}
}1
2
3
4
5
6
7
8
9//vite.config.js 即vue-create脚手架(基于vite)开发的vue项目
server: {
proxy: {
'/api': {//匹配所有以/api开头的请求路径
target: 'http://localhost:3000', // 目标服务器地址
changeOrigin: true, //改变代理服务器请求目标服务器时的host,代理服务器修改host为目标服务器的域名
rewrite: (path) => path.replace(/^\/api/, ''), // 重写路径,移除前缀
}
}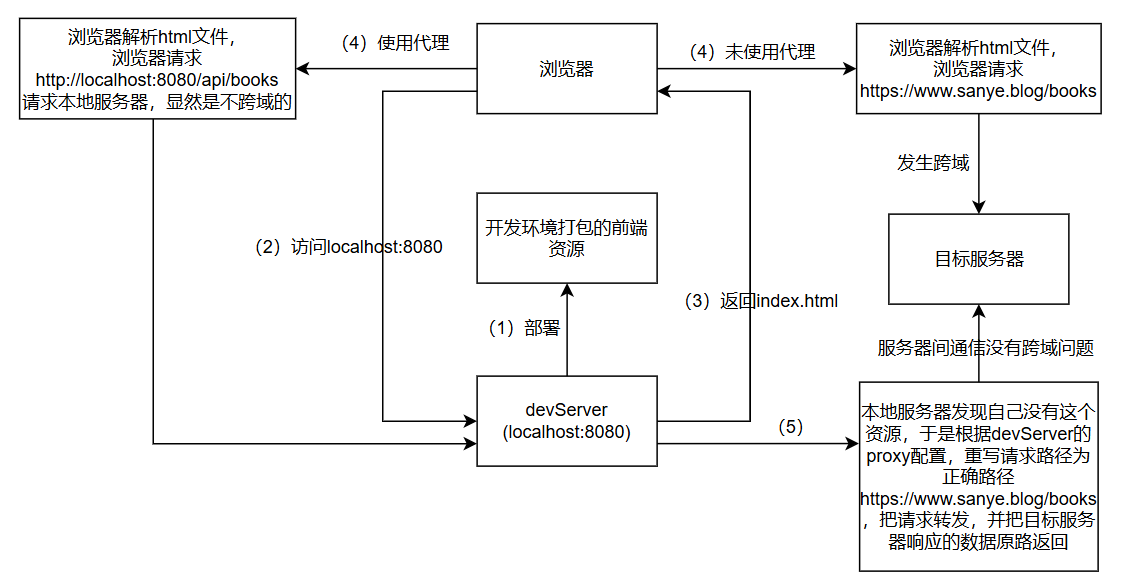
- 可以看到,我们要使用代理,在编写接口时,就不能书写完整的路径,比如就不能直接把请求url写成
https://www.sanye.blog/books,这样必然跨域 - 我们应该把请求写为
/books,部署到本地服务器后加载网页,发起这个请求前,会先自动与域名拼接,实际的请求就变为http://localhost:8080/books,这样就没跨域 - 不过确实,这么操作的话,就是在请求本地服务器中的
books资源,而不是目标服务器中的,如果我们本地服务器中有这个资源(vue-cli中是public目录下有books文件,无后缀),那么本地服务器就会把这个资源返回给浏览器,无论我们是否开启了代理 - 所以我们实际还要添加
/api类似的多余的前缀,来控制我们访问的是本地服务器资源,还是其他服务器上的资源。如果我们请求的的资源在本地服务器不存在,本地服务器会帮我们按照配置的规则进行路径重写,得到正确的请求URL,再向目标服务器请求资源。
- 可以看到,我们要使用代理,在编写接口时,就不能书写完整的路径,比如就不能直接把请求url写成
在服务端开启代理
其实也不是打包后,就不能通过代理来解决跨域问题,如果我们把
打包后的前端资源部署到本地的服务器,比如使用基于node.js的express框架搭建的本地服务器,我们也可以通过配置代理来解决跨域问题。1
2
3
4
5
6
7
8
9
10
11
12const express = require( 'express ')
const app = express()
//其实webpack-dev-server开启代理功能的核心也是这个中间件
const { createProxyMiddleware } = require( 'http-proxy-middleware ');
app.use(express.static( . /public))//引入静态资源
app.use( '/api' ,createProxyMiddleware({
target: ' https:// www.toutiao.com',
changeOrigin:true,
pathRewrite:{
'^/api ' : ''
}
}))总之想要配置代理,就离不开一台允许你配置代理的
服务器,把打包后的前端资源托管到其他平台,我们也无法来配置代理,也就无法解决跨域问题。
CORS
CORS (Cross-Origin Resource Sharing),即跨域资源共享,意思就是虽然你在跨域请求我的资源,但是我还是选择性的共享资源给你,浏览器根据响应头中的特定字段,来决定是否拦截跨域请求返回的数据。
因为需要在响应头上做文章,所以这个工作主要是前后端协调后,由后端负责,至于前后端如何协调,参考简单请求和复杂请求部分。
如何理解简单请求和复杂请求
区别二者的关键,就在于请求方法和请求头,简单请求是在请求方法和请求头上,都有严格要求的请求,违背任何一条要求,都将变为复杂请求。
| 简单请求 | 复杂请求 | |
|---|---|---|
| 请求方法(携带在请求行中) | get,post,head | 除get,post,head外的请求方法 |
| 请求头 | 满足cors安全规范(一般不修改请求头就是安全的)Content-Type 的值仅限于以下三种之一: application/x-www-form-urlencoded multipart/form-data text/plain,且未自定义其他请求头 | 设置了自定义的请求头,或者 Content-Type 的值不是上述三种之一 |
在非跨域情况下,区分二者并没有什么意义,但是在跨域情况下,发送复杂请求前,会先发送一次预检请求,请求方法为options,
在请求头中携带Origin,Access-Control-Request-Method,Access-Control-Request-Headers字段,询问服务器是否接受来自xxx源,请求方法为xxx,请求头为xxx的跨域复杂请求,如果接受,才发送这样的复杂请求。
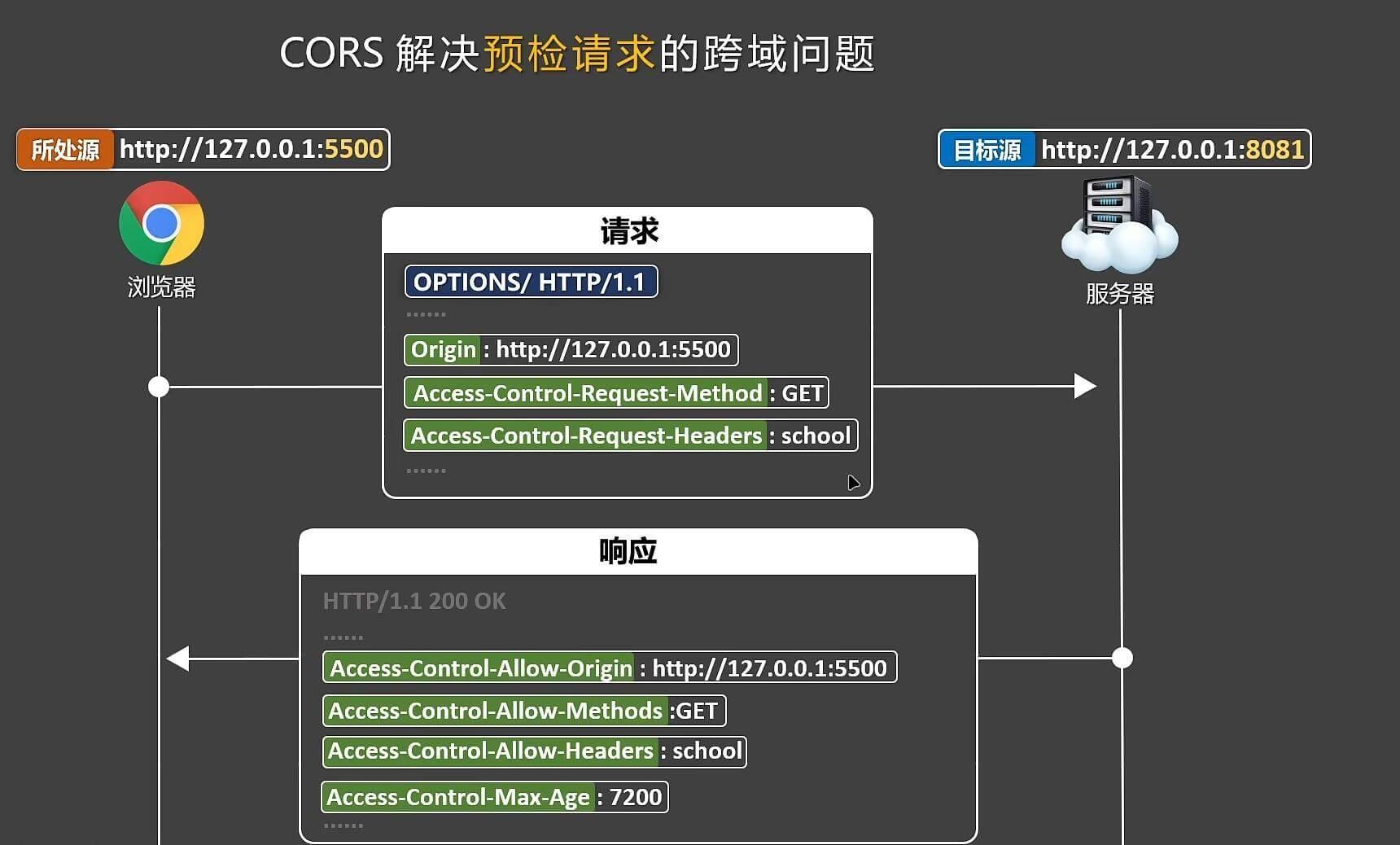
服务端处理代码(以express框架为例)
1 | app.options( '/students ',( req,res)=>{ |
这样处理起来明显比较繁琐,实际上我们借助CORS中间件就能统一处理简单请求和复杂请求(包括预检请求)的跨域问题。
head请求
HTTP请求方法 HEAD ,是一种用于请求资源元信息的请求方法,它与 GET 请求类似,但有一个关键的区别:服务器在响应中不会返回消息体(即实际的内容),只返回头部信息(Headers)。这意味着当你发送一个 HEAD 请求时,你只会收到关于该资源的元数据,例如内容类型、大小、最后修改时间等,而不会收到文档的实际内容。
使用场景
- 检查资源的状态:可以用来检查资源是否存在、获取资源的最新修改时间或其他头部信息,而不必下载整个资源。
- 测试链接的有效性:在不加载整个页面或资源的情况下,验证URL的有效性和可访问性。
- 性能优化:在需要了解文件大小以准备接收之前,可以通过
HEAD请求先获取文件的大小信息。这在处理大文件下载前特别有用,因为它允许客户端决定是否继续下载。 - 缓存验证:可以用来检查本地缓存的副本是否仍然有效,通过比较缓存中的头部信息和服务器返回的头部信息。
vue项目如何部署?
如何部署
前后端分离开发模式下,前后端是独立布署的,前端只需要将最后的构建物,上传至目标服务器的web容器指定的静态目录下即可,我们知道vue项目在构建打包后,是生成一系列的静态文件。
404问题
HTTP 404 错误意味着链接指向的资源不存在,问题在于为什么不存在?且为什么只有history模式下会出现这个问题,而hash模式下不会有?
history模式,刷新页面,前端路由部分会被当作请求URL的一部分发送给服务器,然而服务器并没有相关配置,所以响应404。
而hash模式,前端路由在URL的#后面,不会被当作请求URL的一部分。
要解决使用history路由的项目,刷新页面出现的404问题,必须和后端沟通,当请求的页面不存在时,返回index.html,把页面控制权全交给前端路由。
但是这样有个问题,就是后端服务器不会再响应404错误了,当找不到请求的资源总是会返回index.html,即便请求的资源在前后端中都不存在(即把页面控制权交给前端路由,也没有对应的页面),所以为了避免这种情况,应该在 Vue应用里面覆盖所有的路由情况,最后给出一个 404 页面(虽然说是404页面,但是响应状态码是200,因为返回了index.html),简单的来说404页面需要前端来设计
直接打开页面空白问题
直接打开页面,页面空白本质就是因为js文件加载失败
因为我们开发的是单页面应用程序,需要借助js操作dom来更新页面,而本身的html文件中并没有任何结构,所以如果js文件加载失败,页面就不会有任何结构,所以显示空白。
那为什么js文件会加载失败呢,原因分为两种,一种是加载js文件的路径错误,这通常出现在使用绝对资源路径的情况(使用history路由),为了得到最终的路径还会和盘符(C:或者D:)拼接,所以找不到资源。
还有一种是请求资源的时候跨域了,为什么会跨域了,我们加载的不是本地的js文件文件吗?确实,加载本地资源出现跨域,导致资源加载失败的问题,只会出现在vue3项目中,而vue2项目中不会有这个问题,为什么呢?vue3默认使用vite构建工具,打包后会生成基于esm的代码,浏览器在file://协议下加载esm时,会触更严格的跨域安全策略,导致本地的css,js文件也被视为跨域资源,所以资源加载失败
1 | <!--可以观察到这个模块的type='module',这意味着这个js文件内使用了esm语法(比如import),这个js文件成为了esm--> |
而vue2项目通常使用webpack打包,生成的代码通常以传统脚本的形式加载,此时浏览器对file://协议的跨域闲置比较宽松。