
Vue-Router
在vue2,vue3项目,使用的路由插件都是vue-router,就是语法有所不同。
修改地址栏路径时,切换显示匹配的组件
单页面应用
所有功能在一个html页面上实现,基于前端路由实现
优点:按需更新性能高,开发效率高,用户体验好
缺点:学习成本,首屏加载慢(如果不使用代码分割,加载首屏还会将其他页面的资源一同加载并处理,然后才开始首屏渲染),还不利于SEO。
路由导航
声明式导航router-link
使用vue-router提供的全局组件router-link,替代a标签实现跳转,必须配置to属性指定路径(不需要加#)。本质还是a标签。
1 | <router-link to="/路径值"</router-link> |
能高亮,默认就会提供高亮类名,可以直接设置高亮样式,不需要手动添加类名,高亮类名包括:
router-link-active(模糊匹配,常用)
to="/my"可以匹配/my/b,意思是当前页面的前端路由是/my/b,这个高亮类名就会生效。router-link-exact-active(精确匹配):就必须完全一样,这个高亮类名才会生效。
编程式导航
1 | this.$router.push() |
使用path跳转
push字符串
1
2
3this.$router.push('路由路径')
this.$router.push('/路径?参数名1=参数值1&参数2=参数值2')//传入查询参数
this.$router.push('/路径/参数值')//动态路由传参push对象
1
2
3
4
5
6this.$router.push({path: '路由路径'})
this.$router.push({
path: '/路径',
query: {参数名1:'参数值1',参数名2:'参数值2'} //query必须是一个对象
})//传入查询参数
this.$router.push({path:'/路径', params:{参数名:参数值}})
使用name跳转
适合路径过长的路由,给path路径取名,用name替代path,好处是不用写过长的路径,缺点是只能通过push对象的方式跳转,传参,因为没有path无法拼接成合法的url。
1
2
3
4
5
6
7
8
9
10
11
12
13const routes = [
{
path: '/',
name: 'Home', // 给首页路由命名为 'Home'
component: Home,
},
{
path: '/about',
name: 'About', // 给关于页面路由命名为 'About'
component: About,
},
// 其他路由...
];1
2
3
4
5
6
7
8
9
10
11this.$router.push({
name:"路由名字'
})
this.$router.push({
name:"路由名字',
query: {参数名1:'参数值1',参数名2:'参数值2'}
})
this.$router.push({
name:"路由名字',
params: {参数名1:'参数值1',参数名2:'参数值2'}
})
参数接受
this.$route.query:接收查询参数
this.$route.params:接收动态参数
动态路由传参的前提是组件配置了动态参数。
1
2
3
4
5
6
7const routes = [
{
path: '/about/:a',
component: About,
}
// 其他路由...
];然后跳转传参:
to="/about/3",3就会被赋值给a,然后在About组件中,通过this.$route.params.a访问。如果跳转不穿参:
to="/about",就会报错,如果希望可传参,可不传,则在动态参数后加上?。1
2
3
4
5
6
7const routes = [
{
path: '/about/:a?',
component: About,
}
// 其他路由...
];动态路由的其他意义:让不同的路由对应相同的组件。
嵌套路由
children 属性用于定义嵌套路由。每个子路由的 path 应该相对于其父路由的路径来理解。
1 | { |
重定向redirect
1 | const routes = [ |
路由出口router-view
router-view是vue-router提供的一个全局的组件,是一个可以被替换掉的动态组件。
导航守卫

next()
- 无参数:直接调用
next()表示允许导航继续进行,效果和next(true)是完全等价的,都表示允许导航继续。 - 传递路径或命名路由:
next('/somePath')或next({ name: 'SomeRoute' })用于重定向到另一个位置。 - 传递 false:
next(false)阻止导航继续进行。 - 传递错误对象:
next(error)触发路由错误处理逻辑。
局部守卫
组件内部
beforeRouteEnter
1
2
3
4
5
6
7
8
9export default {
beforeRouteEnter(to, from, next) {
// 在渲染该组件的对应路由被confirm 前调用
// 不能获取组件实例 `this`,因为当守卫执行前,组件实例还没被创建
next(vm => {
// 通过 `vm` 访问组件实例
})
}
}beforeRouteLeave
这个守卫用来阻止用户离开当前路由。比如,你可以用它来提示用户是否有
未保存的更改。1
2
3
4
5
6
7
8
9
10export default {
beforeRouteLeave(to, from, next) {
const answer = window.confirm('Do you really want to leave? you have unsaved changes!')
if (answer) {
next()//确认离开
} else {
next(false)//取消离开
}
}
}beforeRouteUpdate
这个守卫在当前路由改变,但是该组件被复用时调用。举例来说,对于一个带有动态路由参数的路径
/foo/:id,当你从/foo/1导航到/foo/2时,由于会使用同一个组件实例,所以beforeRouteUpdate守卫会在这种情况下被调用。但是如果这个组件实例被缓存了,从别的组件切换到这个组件也不会触发这个钩子。只能借助
activated或者beforeRouteEnter1
2
3
4
5
6
7
8
9
10
11
12export default {
beforeRouteUpdate(to, from, next) {
// 路由改变时重新获取数据
this.fetchData()
next()
},
methods: {
fetchData() {
//获取数据的逻辑
}
}
}可以观察到组件内的路由守卫都以
beforeRoute为前缀,而全局前置守卫和路由独享守卫都只以before为前缀
路由独享守卫beforeEnter
这个路由守卫,是在配置路由的时候书写的,也是路由对象的一个属性,和
path,component等是同一级别。1
2
3
4
5
6
7
8{
path: '/home',
component: home,
beforeEnter:(to,from,next)=>{
console.log(to,from,next)
next()
}
},//这里的to显然是home组件的路由对象,即this.$route
全局守卫
beforeEach
beforeEach即全局前置守卫,在每次导航时都会触发,无论是从一个路由跳转到另一个路由,还是首次进入应用。所有的路由在真正被访问到之前(解析渲染对应组件页面前),都会先经过全局前置守卫,只有全局前置守卫放行了,才会到达对应的页面,或者说才会开始渲染对应的组件。1
2
3
4
5
6
7
8
9
10
11
12
13
14//next()表示放行,next("url")表示拦截到url
router.beforeEach((to, from, next) => {
//前两个是对象(和$route一样 是一个反应式的对象(路由对象)),后一个是函数
//如果要访问的网站to对象的路径:path 不是'/pay', '/myorder'
if (!paths.includes(to.path)) {
next()//放行
} else {
if (store.getters.token) {
next()//如果登录了,放行
} else {
next('/login') //拦截到 登录页面
}
}
})
$route和$router的区别
一个是路由,表示当前页面的路由对象;一个是路由器,记录了所有页面的对应的路由路径。
在组件内可以通过this.$route或得当前组件对应的路径。
404页面
{ path: '*', component: NotFound },路由的匹配顺序是声明顺序,通常写在最后,匹配不到组件就匹配这个组件 。
当我们使用的路由是history路由的时候,这个页面非常有用,因为后端为了防止使用history路由的页面,将前端路由发送到后端导致响应404,所以每当匹配不到资源的时候,后端都返回index.html,这样浏览器就会重新解析html,渲染页面,将路由控制权交给前端路由。但是这样也有缺点,就是如果用户请求的路径,既没有对应的后端资源也没有对应的前端页面,这种情况,确实需要响应404,我们就需要一个404页面来提示用户。
在vue2和vue3中的区别
在vue2中
1 | //router/index.js |
在vue3中
1 | //router/index.js |
import.meta.env.BASE_URL:路由基地址,导入的是vite的环境变量,可以通过修改vite.config.js文件的base属性来改变基地址,不能把import.meta.env.BASE_URL直接替换成'./'这种字面量。
scrollBehavior 是 Vue Router 3.5.0 版本引入的一个功能,允许你定义一个滚动行为的函数,用于在导航时控制页面的滚动位置。
它和routes这个常见的配置项属于同级别的属性。
scrollBehavior 函数接收三个参数:
- to:即将进入的路由对象。
- from:即将离开的路由对象。
- savedPosition:仅当
popstate导航(如用户点击浏览器的前进/后退按钮)时可用。这是一个包含滚动位置的对象(如果有保存的话),比如{top:20}。savedPosition记录的是用户点击前进或后退按钮时,的页面滚动位置
1 | const router = createRouter({ |
这段代码会在用户点击浏览器的前进/后退按钮时恢复之前保存的滚动位置;如果没有保存的位置,则默认滚动到顶部。
创造实例方式
- 一个是使用
构造函数创建router实例,一个是通过函数创造 - 使用的库都是vue-router
- 创造实例的时候传入的都是配置项
路由模式
- vue2中控制路由用
mode属性,history标识历史模式,hash是默认模式 - vue3中控制路由模式用
history属性,createwebHistory表示历史模式,createwebHashHistory表示哈希模式。
获取router/route对象方式
vue2在组件中可以通过
this.$router/$route获取,在js文件中则通过直接导入router的方式实现路由跳转。在vue3中,在普通js文件中,也是通过直接导入router的方式实现路由跳转。在组件中(默认使用setup语法糖),通过useRoute, useRouter这两个api分别获取
当前页面路由对象和路由器对象,因为没有this,所以不能再使用vue2中的语法。1
2
3
4//在js
import router from '@/router';
// 执行导航操作
router.push('/some-path');1
2
3
4
5
6<script setup>
//这些函数依赖于Vue的响应式系统和组件上下文,只能在组件内使用,在普通js文件中无法使用。
import { useRoute, useRouter } from 'vue-router'
const route = useRoute()
const router = useRouter()
</script>要注意的是,在组件内使用
useRoute, useRouter,不能在函数内部使用,只能在setup顶级作用域中使用获得route和router,否则api调用返回的值是undefined。无论是在vue2还是在vue3中,在template中都能通过
$route访问当前页面路由对象。
导航守卫
在 Vue 3 中,如果你使用的是 Vue Router 4,在某些情况下,你可以直接返回值(return或者return true)来代替调用 next(),这使得代码更加简洁,但是也要注意这样会终止导航守卫函数。
1 | router.beforeEach((to, from) => { |
Vuex
在vue2开发过程中使用的状态管理工具。
场景
- 在多处被使用:某个状态在很多个组件中使用(个人信息)
- 多个组件共同维护一份数据比如(购物车)
- 数据传递存在困难用vuex就完事了
优势
- 共同维护同一份数据
- 响应式变化,响应式变化基于vue2的响应式
- 操作简洁
注册
创建vuecli项目时,勾选vuex或者手动添加。
- 安装vuex
- 在src新建文件store,新建文件index.js
- 在index文件中初始化插件:Vue.use(Vuex);创造空仓库,配置仓库。
- 导出store对象,最后在创建根实例的时候传入这个store对象,它最终会被注入到每个组件实例中,也就是说
this.$store是组件实例自己的属性。
1 | // store/index.js |
1 | // src/main.js |
特点:有且只能有一个根仓库,其他的都是子仓库 ,注册在根仓库的modules属性下
四大属性
state
提供唯一的公共数据源
无论组件内外,都是从store对象出发,来拿到state,不过获取store对象的方式不同。
组件内的,可以通过this.$store拿到,在模板内可以直接使用$store(模板内默认去除this),后面的3大属性同理。
组件外则通过import导入:import store from './store',直接拿到store实例,因为在store/index.js中导出了,一方面是为了注册,一方面是为了在组件中使用。
state中的数据的生命周期
初始化:当 Vuex store实例被创建时,定义在 store 中的 state 也会一同被初始化。这意味着一旦应用启动,并创建了 Vuex store 实例,state 就会被初始化并准备好使用。
页面刷新:默认情况下,Vuex 的 state 在页面刷新时,会重新初始化。本质是因为刷新页面会导致 Vue 应用重新加载,从而重新创建 Vuex store 实例,并重新初始化其 state。如果需要在页面刷新后保持 state 数据,可以使用一些持久化存储的方法,如 localStorage 或者 sessionStorage,初始化的时候再从中取数据。
应用运行期间:在应用运行的过程中,state 可以通过 commit mutations 来直接改变,或通过 dispatch actions 后再 commit mutations来间接改变。这是 Vuex 管理状态变化的主要方式,确保状态的变化是可追踪和预测的。
路由变化:当用户在应用的不同路由之间导航时,除非明确改变了 state 或者触发了相关的 mutations/actions,否则 state 不会因为路由变化而自动改变。因为state不是存储再任何组件中的,即便组件因为被切换而被销毁,也不会影响state中的数据。
挂载位置
模块中的state,最终会挂载在根仓库的state中,无论模块是否开启命名空间(开启命名空间是防止命名冲突)
但要注意的是根仓库中的属性直接通过
this.$store.state就能拿到,比如this.$store.state.index,而模块中的属性需要通过this.$store.state.module才能拿到,路径更长,比如购物车模块中的购物车列表,通过this.$store.state.cart.cartList才能拿到。
例子如下:
1 | export default new Vuex.Store({ |
1 | //modules/cart.js |
1 | //modules/user.js |

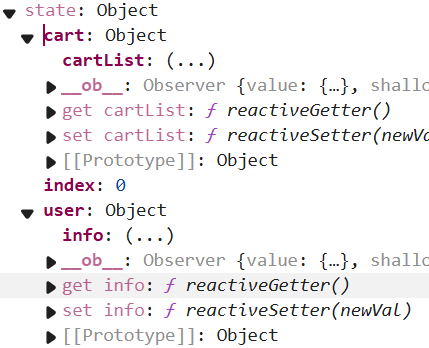
可以看到user模块即便没有开启命名空间,其state中的数据也还是不会直接挂载在this.$store.state下,而是挂载在this.$store.state.user下。
mutations
里面是一些修改/维护state中的数据的函数,只能通过调用这里的函数来修改数据。
参数
第一个参数是state,用来访问state中的数据,也同时说明了mutations只能同步修改数据
1 | mutations: { |
我们在使用mutations中的方法的时候忽略第一个参数,我们传入的参数就是index,比如this.$store.commit('setIndex',1)
挂载位置
是否开启命名空间,也不影响mutations的挂载位置。但是会影响挂载时候的属性名,举个例子:
1 | export default new Vuex.Store({ |
1 | //modules/cart.js |
1 | //modules/user.js |
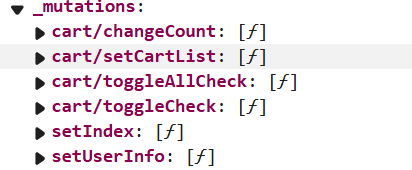
如图所示,cart模块开启了命名空间,所以属性名加上了cart/前缀,而user模块未开启,就不会加上前缀,如同根仓库中的mutations,但是无论开不开启命名空间,它们模块的mutations中的方法都是直接挂载在this.$store._mutations下的
然后我们使用commit调用mutations中的方法,就有:
1 | this.$store.commit(属性名,参数) |
比如:
1 | this.$store.commit('cart/changeCount',3) |
commit是Store实例的自己的属性,值是函数
getter
参数
相当于计算属性,第一个参数也一般是state,第二个参数可以是getters(用来拿到getters中的属性)
挂载位置
是否开启命名空间,也不影响getter的挂载位置。但是会影响挂载时候的属性名,举个例子:
1 | export default new Vuex.Store({ |
1 | //modules/cart.js |
1 | //modules/user.js |

如图所示,cart模块开启了命名空间,所以属性名加上了cart/前缀,而user模块未开启,就不会加上前缀,如同根仓库中的getter。
这一挂载规则就和mutations的挂载规则相同,因为getters本质也是函数啊。
然后我们访问的时候就有:
1 | this.$store.getters[属性名] |
比如:
1 | this.$store.getters['token'] |
actions
里面是一些异步操作/函数
参数
第一个参数是context(上下文):
- 可以通过
context.commit()调用mutations里的方法,来修改state; - 可以通过
context.dispatch()调用actions里的方法; - 可以通过
context.state拿到数据,但是不能直接修改数据,总之就是雨露均沾。
挂载位置
原理和mutations,getters一样(三者本质都是函数啊),是否开启命名空间,也不影响actions的挂载位置,都挂载在Store._actions属性中。
然后调用的时候就有:
1 | this.$store.dispatch('属性名',参数)//类似mutations |
dispatch和commit一样是Store实例的自己的属性,值是函数。
总结
- 无论模块是否开启命名空间,模块中的state都会挂载到store.state上,只不过不是直接挂载到state上,还要加上模块名
- 无论模块是否开启命名空间,模块中的mutations,getters,actions,都会直接挂载到
_mutations/getters/_actions上。但是只有开启了命名空间才会添加前缀。
辅助函数
在我们了解了各个属性在Store实例中的挂载位置后,我们拿到Store实例后,就知道如何访问,使用这四个属性了。
其实vuex还提供了辅助函数来简化操作。
四个属性,分别对应四个辅助函数,mapState,mapMutations,mapActions,mapGetters
辅助函数内部本质其实也是使用this.$store来执行各种操作的,所以只能在组件中使用,因为只有在组件中才能拿到this。
它们的使用方法是类似的。
mapState
mapState返回的是一个对象,这个对象可以有多个属性,属性的值类型都是函数,都是计算属性,内部使用了this.$store来获取state中的数据。
1 | import { mapState } from 'vuex' |
如果,使用辅助函数使用了传递了2个参数的形式,如图,则第一参数是模块名,要求必须开启命名空间。
mapMutations
1 | import { mapMutations } from 'vuex' |
mapGetters
1 | import { mapGetters } from 'vuex' |
Pinia
vue的最新状态管理工具,vuex的替代品。
优点
和Vue3新语法统一,提供符合
组合式风格的API提供更加简单的API(去掉了mutation,合并到actions)
去掉了
modules的概念,替换为一个一个的同级别的store,他们都由pinia管理,创建好的pinia实例最终会在app上注册,也就是vue实例上(app.use(pinia))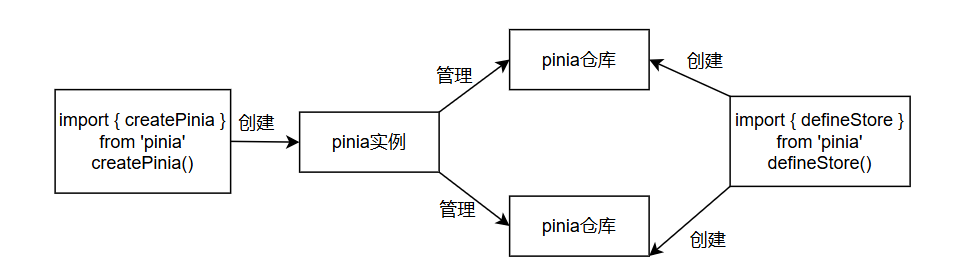
配合TypeScript更加友好,提供可靠的类型推断。
注册
1 | //main.js |
组合式风格
1 | //cart.js |
特点:
- 定义的变量就是state属性
- 定义的计算属性。即computed,就是getters
- 定义的函数,即function(),就是actions,支持异步操作,也支持同步操作
选项式风格
个人还是一味的使用组合式了….
1 | import { defineStore } from 'pinia' |
持久化插件
无论是vuex还是pinia,仓库中的数据是保存在内存中的,如果不使用持久化存储,当页面刷新或者关闭时,数据就会丢失。这是因为这些状态是存储在 JavaScript 运行时的内存中的,一旦页面卸载(比如刷新或关闭),这些数据就会被销毁。
使用步骤
1 | npm i pinia-plugin-persistedstate |
1 | import { createPinia } from 'pinia' |
再指定要持久化的store,对于组合式store,需要在defineStore函数里再传入一个参数(第三个参数),{persist:true}。
对于选项式store,直接添加属性persist:true即可
1 | export const category = defineStore('category',() => {},{persist:true}) |
原理
- 简化了localStorage的相关操作,会自动使用
JSON. stringify/JSON.parse进行序列化/反序列化。值为函数和undefined的属性无法被序列化,Symbol属性和值为Symbol的属性无法被序列化。 - 存储到localStorage的键名默认是
仓库唯一标识。 - 默认把仓库整个state做持久化,可以指定具体哪些数据做持久化。
使用
语法
1 | // 假设在stores/counter.js中定义了一个仓库 |
1 | //在组件中使用 |
- router的
useRoute和useRouter只能在组件中使用,在想要在js文件中使用,就必须引入router对象。 - 而pinia就不同了,无论在是组件还是js文件中,都能通过引入并调用
useXXXStore的方式,获得store对象,然后才能访问其中的状态,调用其中提供的方法。 - 不过,在js 文件(非 Vue 组件)中使用 Pinia store 需要一些额外的步骤,因为你没有 Vue 组件的上下文(比如
setup()函数)。需要确保 Pinia 已经被安装并且可以访问到,所以最好不要写到js文件的全局作用域中。
与vuex的区别
- vue2中要使用vuex中的哪个数据,调用哪个方法,都是单独获取,而Vue3是一个一个
store整体导入使用。 - 在vue2的组件中,通过
this.$store就能访问到store对象,而在js文件中就需要手动导入。
启用命名空间
在 Pinia 中,无需手动启用命名空间特性即可避免 Store 之间的命名冲突,这是其设计哲学的一部分。
Pinia 通过 唯一 Store ID 自动实现命名空间隔离。每个 Store 在定义时必须指定一个全局唯一的 ID(字符串),该 ID 会作为所有状态的命名空间前缀。
1 | // 定义 user 模块 |
若两个 Store 使用相同 ID(如 defineStore('user', ...) 重复),构建时会直接报错。
Vue-cli
是什么
vue使用webpack进行模块化开发,但是webpack的配置工作是一个很繁琐的过程,所以出现了vue-cli这个脚手架工具,它可以帮助我们快速创建一个开发vue项目的标准化webpack配置。
快速开始
1 | npm i @vue/cli -g//全局安装,安装一次就行,之后就可以在任意目录执行以下指令 |
项目结构
node_modules:存储项目的所有 npm 依赖包。
public:存放
静态资源,如 index.html 和 favicon.ico,这些文件不会被 webpack 处理,而是会直接被打包进最终文件。dist:项目打包后的代码:
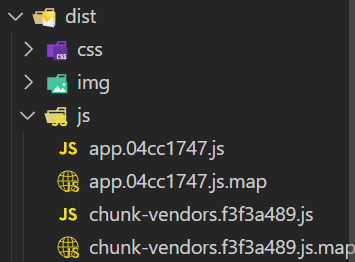
- 其中
app.04cc1747.js包含了应用的主要逻辑和代码。它通常是 Webpack 将Vue 组件、路由配置、入口文件等打包后生成的主 JavaScript 文件。 app.04cc1747.js.map是一个 Source Map 文件,与app.04cc1747.js 对应。Source Map 的主要作用是帮助开发者在调试时,将压缩或转换后的代码映射回原始源代码,便于定位错误和调试。chunk-vendors.f3f3a489.js这个文件包含了项目中使用的第三方库和依赖(如 Vue、Vuex、Vue Router 等)的代码。通过将这些公共依赖单独打包成一个文件,可以提高代码的复用性和加载性能。chunk-vendors.f3f3a489.js.map是chunk-vendors.f3f3a489.js对应的 Source Map 文件,用于帮助开发者在调试时追踪第三方库中的问题。
- 其中
src:源代码的主要目录
assets:用于存放静态资源文件,如图片、字体等,会被 webpack 处理。
components :存放 .vue 单文件组件
views:存放页面
App.vue:根组件,整个应用的入口点。
main.js:应用程序的入口脚本,通常在这里创建 Vue 实例(根实例)。
1
2
3
4
5new Vue({
router,
store,
render: h => h(App)
}).$mount('#app')
package.json:项目元数据和依赖关系列表,以及 npm 脚本(script)。
vue.config.js:Vue CLI 的可选配置文件,用于自定义构建设置
babel.config.js:Babel 的配置文件,用于转换 ES6+ 代码。它可以帮助你将现代 JavaScript 特性(ES6+)转换为向后兼容的 JavaScript 版本。
json-server
是一个轻量级的 Node.js 模块,可以让你快速地启动一个具有 REST API 的 JSON 文件数据库服务器。它提供了一个简单的、可立即使用的后端。
1 | npm install -g json-server |
在项目根目录下创建一个文件,比如 db.json,并填充一些数据
1 | { |
在db.json文件所在目录下执行json-server --watch db.json,这会启动一个默认监听在http://localhost:3000的服务器
使用各种 HTTP 请求工具(如 Postman 或 cURL)或前端框架中的 AJAX 请求来与之交互,比如可以发送一个 GET 请求到http://localhost:3000/posts来获取所有的帖子
eslint,eslint扩展,prettier
eslint扩展
ESLint 扩展的作用是在编码的时候,就提示代码存在的问题,通常依赖于项目中的本地安装的 ESLint。这意味着它会在项目的node_modules目录中寻找 ESLint。如果您没有在项目中安装 ESLint,VSCode 的 ESLint 扩展可能会无法正常工作。
eslint和prettier
我们在创建vue3项目的时候,就能根据vue-create脚手架的提示,快速的下载好eslint和prettier所需的包
1 | "devDependencies": { |
然后目录下还会多出.eslintrc.cjs和.prettierrc.json文件,.eslintrc.cjs是ESLint 的配置文件,主要用于代码质量检查和部分风格约束(如变量未声明、未使用的导入等);.prettierrc.json是Prettier 的配置文件,专注于代码格式化(如缩进、引号、换行符等),不涉及代码逻辑问题。
1 | //.eslintrc.cjs文件初始内容 |
1 | //.prettierrc.json文件初始内容 |
setting.json
同时项目根目录下的.vscode文件中也会多出一个setting.json文件(相比于不使用eslint和prettier的项目),其实也不需要我们过于操心这个文件,一般保持默认配置就好。
1 | //setting.json |
保存文件时,第一步,Prettier 自动格式化代码(formatOnSave);第二步,用户手动触发代码修复(codeActionsOnSave:explicit)
集成prettier配置到eslint
此时,我们编码的时候,vscode并不会提示我们代码不符合prettier规范,因为我们没安装prettier扩展。
但是我们安装了eslint扩展啊,只要把prettier的配置代码集成到eslint的配置代码中就好了,这样编写代码的时候,也会有prettier规范提示。
1 | /* eslint-env node */ |
如果发现修改.eslintrc.cjs保存后没有效果,则可以尝试重启vscode,重新加载这个配置文件。
husky
是什么
husky能够帮助我们轻松的设置git hooks,git hooks就是一系列的钩子函数,类似vue的生命周期函数,会在git的特定阶段触发。
Husky 将 Git 原生钩子(如 pre-commit)的配置,从 .git/hooks 迁移到项目根目录的 .husky 文件夹中,通过脚本化的方式统一管理,避免钩子文件被 Git 忽略或覆盖的问题。
husky通常与lint-staged配套使用,lint-staged 是一个针对 Git 暂存区(Staged Files)运行代码检查(Linters)和格式化工具的工具。它通过仅对即将提交的代码,进行增量检查,避免全量扫描,从而显著提升校验效率。例如,在提交前仅对修改过的 .js 文件运行 ESLint,而不是整个项目。
lint-staged 本身不依赖 ESLint,但通常与 ESLint 结合使用。其核心功能是按需调用不同的代码检查工具,具体支持的 Linter 包括:ESLint,Prettier,Stylelint,TSLint(TypeScript,已逐渐被 ESLint 替代)
使用步骤
安装:
下载到开发依赖
1 | npm install husky lint-staged --save-dev |
初始化:要注意的是,再初始化之前,需要先确保git仓库存在,Husky 的核心功能是管理 Git 钩子(Git Hooks),而 Git 钩子本身是 Git 仓库的组成部分。只有当项目是 Git 仓库时,Husky 才能通过修改 Git 配置(如 core.hookspath)将钩子脚本的存储路径从 .git/hooks 重定向到 .husky 目录。
1 | npx husky init # v9+版本需执行此命令生成.husky目录[7,9](@ref) |
我们执行这个初始化命令后,发现根目录下多出来一个名为.husky的文件夹,.husky/_ 目录下通常包含 husky.sh 等脚本文件,用于统一管理 Git 钩子的执行环境,_ 目录内容由 Husky 自动维护,手动修改可能导致钩子功能异常,简单的来说,不需要我们管理,操心。
配置钩子脚本:在pre-commit文件中书写:
1 | npx lint-staged |
然后再我们提交代码(commit)之前,这个命令就会被执行
与代码检查工具集成:在 package.json 中配置 lint-staged,这样我们才知道执行npx lint-staged,具体做了什么
1 | { |
eslint --fix:使用 ESLint 自动修复可修复的代码问题(如语法错误、风格问题),这行命令在下载好eslint后是可以直接执行的
prettier --write:使用 Prettier 对文件进行格式化(如缩进、引号、换行符等),这行命令在下载好prettier后是也可以直接执行的
vetur
Vetur插件,是一个为Vue.js项目提供支持的Visual Studio Code(VS Code)插件,适用于vue2。
功能
- 语法高亮:Vetur插件为Vue.js文件提供了语法高亮,让你的代码更易于阅读和理解
- 智能补全:当你输入Vue组件或属性时,它会自动提示可用选项,并提供文档信息
- 代码导航:Vetur插件可以帮助你更轻松地导航和理解Vue.js项目的结构。你可以点击组件名称或引用,快速跳转到相关的文件。
- 语法检查:Vetur插件集成了ESLint和TSLint,可以帮助你在编码时捕获潜在的错误和不规范的代码风格。
问题
Vetur的语法检查会认为vue3的一些新特性,比如可以有两个根元素,v-model:xxx=' xxx'为语法错误。
解决办法:打开设置,搜索 Vetur › Validation: Template ,关闭语法检查,本质上修改扩展设置。
组件样式渗透
背景
scoped只会给当前组件内的标签元素,添加唯一的data-v-hash属性
父组件通过插槽,传递给子组件的内容(即父组件模板中直接编写的插槽内容),会被父组件的scoped样式处理,添加父组件的data-v-hash属性;而子组件内部模板中的内容(包括默认插槽或具名插槽),则由子组件自身的scoped处理,添加子组件的data-v-hash属性。
1 | <!-- 父组件模板 --> |
编译后,父组件的<div class="slot-content">会被添加父组件的data-v-xxx属性,如:<div class="slot-content" data-v-xxx>。若子组件自身模板中包含插槽(如<slot>),且存在默认结构,则这部分内容由子组件的scoped处理,添加子组件的data-v-yyy属性。
scoped还会给当前组件内的所有选择器加上 属性选择。
父组件内如果使用了scoped,父组件内书写的样式因为默认添加了属性选择,所以不会影响子组件内部的元素,因为子组件可能有自己的data-v-yyy属性,或者压根没有data-v-hash属性。
案例
如果在当前组件内使用了scoped的情况下,想要修改子组件内的样式,就可以使用样式渗透,下面举个项目中的例子
1 | <div class="editor"> |
1 | .editor { |
显然,quill-editor,这个富文本组件中存在类名为ql-editor的标签,但是因为我们在组件中开启了scoped,所以不能直接使用:
1 | .editor { |
来修改quill-editor组件中的元素,因为编译后的样式会变为:
1 | .editor[data-v-8a25066b] .ql-editor[data-v-8a25066b] { |
但是这个富文本组件中,类名为ql-editor的标签并没有添加v-data-hash属性,所以,这个样式不会生效。
但是如果我们使用了样式渗透,编译后的样式代码就会变为:
1 | .editor[data-v-8a25066b] .ql-editor { |
显然,这样是能够生效的。
小结
由此我们可以看出,使用样式渗透,就是为了解决因为组件内开启了scoped,导致无法直接修改子组件内元素样式的问题。
样式渗透的语法
然而,样式渗透的语法分别是如何的呢?
原生 CSS:>>>
直接作用于子组件内部元素,但部分预处理器可能不支持:
1 | /* 父组件样式 */ |
编译后:.parent[data-v-xxx] .child-inner
适用场景:原生 CSS 项目
预处理器兼容语法:/deep/
通用性更强,支持 SASS/LESS 等:
1 | .parent /deep/ .child-inner { |
编译后:.parent[data-v-xxx] .child-inner
注意:在 Vue3 中已废弃
Vue2 专用语法:::v-deep
与 /deep/ 等价,但语义更明确:
1 | .parent::v-deep .child-inner { |
我们观察到::v-deep是附加在.parent后面的,这表明了.parent就是父组件中的元素,而 .child-inner 是子组件中的目标元素
编译后:.parent[data-v-xxx] .child-inner
适用场景:Vue2 项目升级过渡期
Vue3 样式穿透语法
Vue3 统一使用 CSS 伪类 :deep(),废弃了 >>> 和 /deep/
1 | /* 修改子组件内部的 .child-inner 样式 */ |
编译后:.parent[data-v-xxx] .child-inner
优势:
- 语法标准化,符合 CSS 规范
- 支持嵌套和动态选择器
富文本编辑器VueQuill
是什么
VueQuill 是基于 Quill.js 的 Vue 3 专用富文本编辑器组件,它将 Quill.js 的功能封装为 Vue 的响应式组件,提供与 Vue 生态无缝集成的开发体验。Quill.js 本身以轻量、模块化和高扩展性著称,而 VueQuill 在此基础上进一步优化了配置方式和 API 设计。
特点如下:
- 支持
v-model双向绑定,直接通过content属性管理富文本数据 - 响应式更新机制与 Vue 的生命周期完美契合,便于状态管理
示例:
1 | <template> |
- 可通过
options.modules.toolbar配置工具栏按钮(如加粗、列表、图片上传等) - 支持按需加载功能模块(如代码高亮、表格插入),减少打包体积
示例:
1 | const editorOptions = { |
使用步骤
安装依赖:
1
npm install @vueup/vue-quill quill --save
全局或局部引入组件:
全局注册:
1
2
3import { QuillEditor } from '@vueup/vue-quill';//引入的是一个组件
import '@vueup/vue-quill/dist/vue-quill.snow.css';
app.component('QuillEditor', QuillEditor);局部引入:
1
2
3
4
5
6<script setup>
// 导入所需的css文件
import '@vueup/vue-quill/dist/vue-quill.snow.css';
// 导入富文本编辑器组件
import { QuillEditor } from '@vueup/vue-quill';
</script>在模板中使用:
1
2
3
4
5
6
7
8
9
10<div class="editor">
<!-- 通过ref拿到quillEditor组件实例 -->
<quill-editor
ref="editorRef"
v-model:content="formModel.content"
theme="snow"
content-type="html"
>
</quill-editor>
</div>常用api:
editorRef.value.setHTML(''),清空编辑器的内容