
计组
原码补码反码

如果一个数是正数,那么它的原码、反码和补码都是一样的
对于负数,计算其补码的过程稍微复杂一些。
找到该数的原码:首先写出该负数的绝对值的二进制表示,然后在最前面加上符号位
1来表示这是一个负数,然后就得到这个数的原码,所以说原码也是有符号位的。例如,对于
-1022,其绝对值1022的二进制表示为1111 1111 10,因此-1022的原码为11111111110。题目要求的是32位,所以我们需要补零,向前补零,得到
0000 0000 0000 0000 0000 0111 1111 1110求反码:将原码除符号位外的所有位取反(即0变1,1变0),补零后的符号位已经不是第一位了,但是我们还是要记住符号位是第几位,因为我们不对符号位取反,得到
1111 1111 1111 1111 1111 1000 0000 0001,观察到先前补的0也取反了。反码加1得到补码:在反码的基础上加1,得到
1111 1111 1111 1111 1111 1000 0000 0010
最后转化成16进制就是FFFF FC02
要注意的是题目要求的是32位补码,我们可以在原码的时候补零,也可以在反码或者补码的时候补零,但是最终得到的结果缺不同,因为从原码到反码有取反的过程,如果在原码的时候补零,这些零会被取反,但是在反码和补码的时候,这些零不会被取反,所以得到完全不同的结果,因为在原码补零的时候不会影响最终的值,所以在原码补零的时候是正确的。
CPU
1 | 一般意义上,64位处理器指的是处理器的( )是64位的 |
般意义上,64位处理器,指的是处理器的地址总线是64位的。这意味着CPU可以直接寻址的地址空间大小为2^64,这是一个非常大的地址空间,足以支持现代计算机系统中极大的内存容量(计组基础太差,只能靠记忆….)
数据结构
数组 链表
1 | 1.执行以下代码段(程序已包含所有必需的头文件)会输出什么结果。() |
因为a[0][2]赋值了字符' '(空格),所以上述执行后相当于a[2][3] = {{'a', 'b', ' '}, {'c', 'd', '\0'}};
%s 格式说明符用于打印以 \0 结尾的字符串。在 C 语言中,%s 会从提供的地址开始读取字符,直到遇到第一个字符串结束符 \0。
但是这里传递给 printf 的是 a,而不是 a[0] 或 a[1]。a 是一个二维数组,但在表达式中使用时,它会被解释为其首元素的地址,即 a[0] 的地址。因此,printf("%s", a) 实际上等价于 printf("%s", a[0]),所以输出的是字符串"ab cd"。
如果不执行a[0][2] = ' ';,输出的结果就是ab,因为a[0][2]是结束字符,遇到它就不会继续输出了。
1 | 2.对于一维整形数组 a ,以下描述正确的是() |
定义一个数组语法是int a[10],A选项错误
在C/C++语言中数组的大小不能是动态的,所以不能传入一个变量来定义一个数组,而在js等语言中,设置数组大小是可以传入值的,B,C选项错误。而D选项的SIZE看似是变量,但其实是不可随意改变的,因为是通过宏定义的。所以选D
1 | 3.将两个长度为 len1 和 len2 的升序链表,合并为一个长度为 len1+len2 的降序列表,采用归并算法,在最坏情况下,比较操作的次数与()最接近 |
无论是合并有序数组还是有序链表,如果2个数组或者链表,都还有剩余的未确定元素,则就要进行一次比较,确定一个元素放入最终数组或者链表;最坏的情况就是2个数组或者链表的元素数目相同,且对于后续的每次取元素,都是轮流取出一个元素,最后依次比较中,两个数组或者链表都只剩下一个元素,这种情况,需要比较len1+len2次。
最好的情况就是,每次比较,取出的都是同一个数组或者链表的元素,直至这个链表或者数组的元素取空,因为另一个链表是有序的,所以确定后续元素就不需要比较了,这种情况的比较次数就是min(len1,len2)次
1 | 4.以下关于链表和数组说法正确的是() |
堆内存是用来存放由new创建的对象或者数组, 栈内存是用来存放在函数中定义的一些基本类型的变量和对象的引用,所以A选项正确。
数组插入元素的平均时间复杂度是O(n),但是如果在数组末尾插入元素,因为不需要移动元素,所以事件复杂度是O(1),所以B选项是错误的,没有注明是平均时间复杂度。C选项,同样也是,没有注明是平均时间复杂度。
D选项错误,因为LinkedList是基于数组和链表存在的,增删要更快,不过这属于是Java的知识了。
1 | 5.下列哪些容器可以使用数组,但不能使用链表来实现? |
Map或者Dict可以按key索引值,这个只有数组能实现,链表不能,所以选D。
队列
1 | 7.用链表方式存储的队列,在进行插入运算时 ( ). |
主要看链队列是否有头节点,有头节点的情况,即便队列为空,插入结点也只会修改rear指向和头结点指向;没有头节点,在插入第一个元素时,会同时修改front和rear,初始时(没有结点的时候),二者都指向null。
1 | 8.数组Q[n]用来表示一个循环队列,f为当前队列头元素的前一位置,r为队尾元素的位置,假定队列中元素的个数小于n,计算队列中元素的公式为()。 |
这道题和我们解除到的循环队列有所不同,f不指向队头元素,r不指向队尾下一个元素,但是没关系,f+1不就指向队头元素,r+1不就指向队尾下一个元素吗,然后我们带入公式就可以得到,元素的个数等于(r+1+n-(f+1))%n,两个指针都向前移动一位,那他们之间的差也不会变,所以选D。
1 | 9.已知循环队列存储在一维数组A[0..n-1]中,且队列非空时 front 和 rear 分别指向队头和队尾元素。若初始时队列为空,且要求第 1 个进入队列的元素存储在A[0]处,则初始时 front和 rear 的值分别是( )。 |
插入时,队头指针不变,队尾指针后移一位。该题约定队列非空时,front 和 rear 分别指向队头和队尾元素,即插入第一个元素在下标为0的位置后,队头队尾指针皆指向A[0],此时可以反推出插入前,队头指针仍旧指向下标0,而队尾指针应指向前一位,也就是下标n-1的位置。所以选B
二叉树
1 | 10.以下说法正确的是( )。 |
最这种罕见的题目,最快的方法就是寻找特例加排除法。
1 | A |
比如这颗二叉树,先序遍历的结果是AB,中序遍历的结果是BA,这样就直接排除A,B,D选项。
1 | 11.下面关于二叉搜索树正确的说法包括________。 |
待删除节点有左子树和右子树时,可以使用左子树的最大值节点或者右子树的最小值结点替换待删除节点。所以A选项错误。
给出一颗二叉搜索树的前序或者后续遍历,就能通过排序得到它的中序遍历,然后就能确定这棵二叉搜索树。
给定一棵二叉搜索树,根据节点值大小排序z和需要做一次中序遍历就可以了,其时间复杂度为 O(n),时间复杂度是线性的,这里 n 表示树中节点的数量。
如果允许额外的存储空间,可以先进行中序遍历生成一个排好序的数组(时间复杂度线性的过程),然后不断的找mid节点作为根来构造平衡树就是线性的,如果不允许额外空间只能靠旋转的话无法用线性时间。
1 | 12.由树转化成二叉树,该二叉树的右子树不一定为空。( ) |
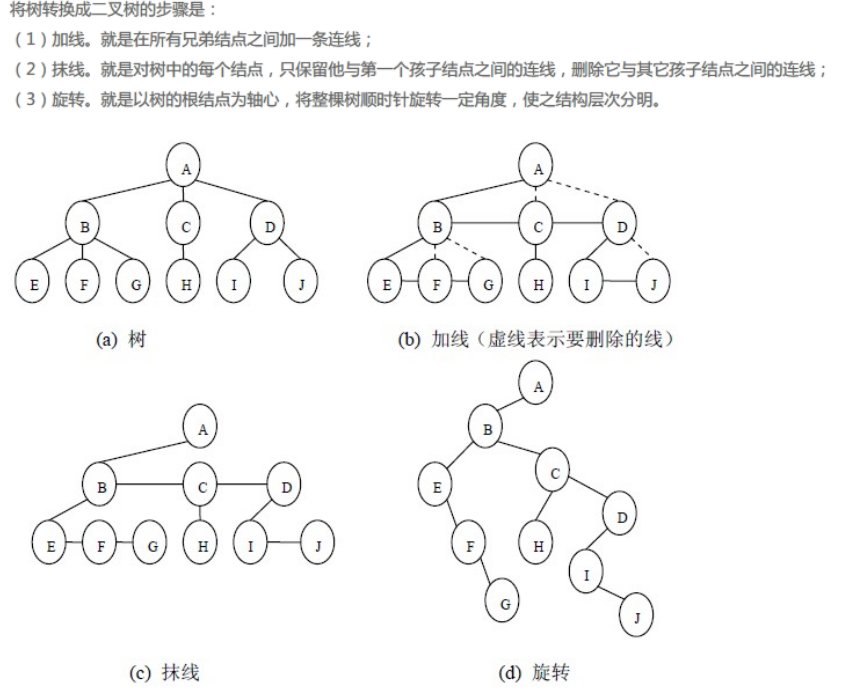
由一般树(非二叉树)转换成二叉树一定没有右子树。
其他
1.线性查找数组的某个元素的空间复杂度
- 输入数据:不计入空间复杂度,因为这部分空间是必须的,无论使用何种算法。
- 额外空间:线性查找通常只需要几个额外的变量来进行操作,比如用于计数的索引变量、存储目标值等。这些额外变量的数量与输入数组的大小无关。
因此,线性查找的空间复杂度,主要是由那些固定数量的额外变量决定的,这意味着无论数组多大,使用的额外空间量都是恒定的,也就是说空间复杂度是O(1)
计算机网络
IP
1 | 要判断IP地址是否在同一个网络,下列哪一项运算正确?( B ) |
将ip地址和子网掩码进行按位与运算,能够准确提取出ip地址的网络地址,所以我们先要知道ip地址的子网掩码,或者说ip地址是什么类型的ip地址,然后进行按位与运算,最终ip地址的主机号部分都会变成0,而网络号的部分则保持不变,如果2个ip地址在同一网络,那么它们的网络号应该是相同的,也就是说最终按位与运算的结果是相同的。
加密解密
1 | 在公钥密码体制中,不公开的是( B ) |
公钥密码体制,也就是使用公钥加密,私钥解密,也就是非对称加密。每个用户都有一对密钥:公钥和私钥。公钥是公开的,可以分发给任何人,而私钥必须严格保密,不能泄露。这样,当有人想发送加密信息给用户时,他们可以用用户的公钥加密,而用户用自己的私钥解密。加密算法一般来说也是公开,比如RSA、ECC这些算法都是公开的,安全性不依赖于算法的保密,而是依赖于密钥的保密。
要注意的是只有非对称加密中才有公钥和私钥的概念,也就是说涉及到了公钥或者私钥,说的就是非对称加密。在对称加密中,只有密钥这一个概念。
html
超文本
含有其他文本的链接的文本
标签
audio和video
这是HTML5新增的功能,允许直接在网页中直接嵌入音频和视频文件,无需额外的插件(告别flash时代)。
source
不使用audio或者video标签自身的src属性,而是内嵌多个source 标签,可以为同一个视频,音频文件提供多种格式,以确保兼容不同的浏览器,浏览器会按照 <source> 标签的顺序尝试加载支持的格式。
1 | <video controls> |
form
1 | <form id="myForm" action="https://www.bilibili.com/" method="get"> |
现象
在上面这例子中,输入tom,123,点击登录后,就会跳转到https://www.bilibili.com页面,使用get方法发起请求并携带查询参数:https://www.bilibili.com/?username=tom&password=123
form标签的几个重要属性
method:规定用于发送表单数据的http方法,可取值有:post和getaction:指定接收,并处理表单数据的URL,点击提交表单,页面会跳转到这个url。enctype:规定在发送表单数据之前,如何对其编码,可取值有:application/x-www-form-urlencoded:这是默认的编码类型。当使用这种编码类型时,浏览器会将表单中的数据进行 URL 编码(也称为百分号编码),即将非字母,非数字字符转换为%后跟两位十六进制数的形式。键值对之间用&连接,键和值之间用=连接。适用于大多数情况下的普通表单提交,特别是文本数据。multipart/form-data:这种编码类型主要用于支持文件上传的情况,它不对二进制数据进行编码,而是将每个表单字段作为单独的部分(part)发送,每个部分都有自己的头部信息来描述其内容类型、名称等。这使得它可以处理各种类型的文件以及文本数据。1
2
3
4
5
6
7
8
9
10
11
12--boundary
Content-Disposition: form-data; name="field1"
value1 //值
--boundary
Content-Disposition: form-data; name="fileField"; filename="example.txt"
Content-Type: text/plain
(binary data) //二进制数据
--boundary--text/plain:这种编码类型主要用于调试目的,因为它简单地将数据按原样发送,仅用换行符分隔各个键值对。表单数据可能会被格式化为如下形式:1
2name=John Doe
age=30
a
重要属性
target属性:指定新标签的打开方式
_self:默认值,默认在当前页面打开_blank:在新的标签页打开
title属性:鼠标悬浮显示的额外信息
href属性
- url:跳转到指定页面,或者下载文件
- #: 点击跳转到当前页面顶部
- #id:点击跳转到当前页面添加了该id的元素的位置,起到一个导航的作用
download属性:
值为保存的文件名
用于提示浏览器下载目标 URL,而不是导航到该 URL,存在跨域限制,跨域则失效
在
file协议加载的页面下这个属性也会失效;比如如果a标签的
href指向一张图片,且未指定download属性,那么点击这个a标签就是预览图片;如果指定download属性,但是未传值,点击a标签会保存文件,保存的文件名是默认文件名,如果给download属性传值,就能指定保存的时候文件的名字。
rel属性
rel 值 作用描述 示例代码 nofollow告诉搜索引擎不要跟踪此链接,也就是说此链接对应的页面,不参与本页面的SEO。如果自己的博客中包含指向低质量或垃圾网站的链接,使用 nofollow可以减少这些链接对你的网站造成负面影响的风险。<a href="comments.html" rel="nofollow">用户评论</a>noopener防止新页面通过 window.opener访问本页,也就是通过a标签,新打开的页面(window)no(没有)opener(打开此页面的页面)属性<a href="external.html" rel="noopener" target="_blank">外部链接</a>noreferrer隐藏访问来源的 Referer头部,当在 HTML 的<a>标签中使用rel="noreferrer"属性时,点击该链接发送的请求中不会包含当前页面的 URL(即Referer头会被移除)<a href="login.html" rel="noreferrer">安全登录</a>
注意
是个内联元素,但是内部可以放除了a的任意元素,因为交互元素不允许嵌套使用。
阻止a标签默认跳转
为<a>标签添加一个 onclick 事件处理器,然后在该处理器中调用 event.preventDefault() 方法来阻止默认行为。
1 | <body> |
a标签常用伪类
- a:link:未被访问
- a:visited:已被访问
- a:hover:鼠标悬浮
- a:active:鼠标点击未松开时
因为浏览器默认会对已访问过的链接应用visited伪类样式,可能覆盖了hover伪类样式
将visited伪类样式的定义放在hover伪类样式之前,比如a:visited{},a:hover{},后面的样式会覆盖前面的样式。
样式的正确书写顺序:a:link->a:visited->a:hover->a:active
input
step属性:规定输入字段的合法数字间隔,step属性的值不能为负数或0,否则默认转化为1;
该属性可以配合max,min属性来创建合法值得范围。step,max,min属性适用于
<input>类型有:number,range,date,datetime,month,time,week。1
<input type="number" min="1" max="10" step="2">
readonly属性:
添加了该属性的表单项只可读,可以获得焦点(点击有outline)
无法通过页面交互修改值,可以通过js修改值
表单项的值会被发送给后端。
1
2
3
4<form action="/submit" method="post">
<input type="text" name="username" value="JohnDoe" readonly>
<input type="submit" value="Submit">
</form>
disabled属性:
无法获得焦点
无法通过页面修改值,可以通过js修改值,
表单项的值不会发给后端,意思就是这个表单项不要了作废了。
1
2
3
4<form action="/submit" method="post">
<input type="text" name="username" value="JohnDoe" disabled>
<input type="submit" value="Submit">
</form>
type
- 滑块类型:range
- 日期
- date:选择日期,包括年月日
- month:选择日期,月年
- week:选择周和年
- time:选择时间
- datetime-local:选择年月日+小时分钟
- datetime:没有这个类型
特殊标签
<(less than),小于号>(greater than),大于号
meta标签
meta标签通常位于head标签中,因为它的主要作用是提供关于文档的元信息(metadata),例如字符编码、页面描述、关键词、作者信息等。这些信息通常是为浏览器、搜索引擎或其他工具服务的,而不是直接显示在页面上的内容。然而,meta标签并不严格要求必须位于head标签中。根据 HTML 规范,虽然推荐将meta放在 head 中,但即使它出现在body 标签中,浏览器通常也能解析并处理它。不过,这种用法并不符合最佳实践,可能会导致不可预期的行为。
name/content
这两个属性是成对出现的
1 | <meta name="author" content="aaa@mail.abc.com">//用来表示网页的作者的名字,例如某个组织或者机构。 |
http-equiv/content
1 | <meta http-equiv="Content-Type" content="text/html;charset=utf-8">//用来声明文档类型和字符集 |
link标签
位于 HTML <head> 中,用于建立 当前文档与外部资源的关系。
link标签和a标签都同归href属性链接资源到文档,而且这2个标签都有rel属性,rel 属性是 "relationship" 的缩写,用于指定当前文档与被链接资源之间的关系
| rel值 | 作用描述 | 示例代码 |
|---|---|---|
stylesheet | 引入 CSS 样式表 | <link rel="stylesheet" href="styles.css"> |
icon | 设置网站图标(favicon) | <link rel="icon" href="favicon.ico"> |
preload | 强制浏览器预加载关键资源(如字体、图片) | <link rel="preload" href="font.woff2" as="font" type="font/woff2"> |
manifest | 链接 PWA 的清单文件 | <link rel="manifest" href="manifest.json"> |
dns-prefetch | 提前解析外部域名 DNS | <link rel="dns-prefetch" href="https://api.example.com"> |
apple-touch-icon | 设定 iOS 主屏图标 | <link rel="apple-touch-icon" href="icon-180x180.png" sizes="180x180"> |
其他标签
li标签:必须放在
ul/ol中,li中可以放li,但不能直接放li,必须先放入ul/ol。p标签不能内嵌任何
块级元素,内部只能放文本或者行内标签,就是不能放块级元素。1
2<!-- 不正确的用法 -->
<p>这是一个段落。<div>这是一个不应该出现在p标签内的div块。</div></p>pre元素可定义预格式化的文本(预排版)。被包围在pre元素中的文本通常会保留空格和换行符。而文本也会呈现为等宽字体。
一般网页设计中logo部分会由
h1标签组成,主要是由于seo的优化,方便爬虫抓取网页信息,由此可见,爬虫会优先抓取<h>系列标签,像常见的p标签也会优先抓取可以获得焦点的标签:
<div contenteditable="true">我可以</div><p tabindex="1">我可以</p>,如果tabindex的值不为-1,那么这个标签就能通过tab键获得焦点- input标签
canvas绘制的图形不是dom元素,无法像操作dom一样操作修改。而svg是直接绘制dom元素,可以操作修改
书写规范
id属性的值不能为纯数字
如果一个
<li>元素之后紧跟另一个<li>元素,或在父元素中没有其他更多内容,则结束标签可以省略
1 | <ul> |
标签之间不能 有空格
1
2< button >some text< / button >//错误的
<button>some text</button>//正确的<p><b>警告!以下代码可能包含威胁!</b></p>是不符合规范的。根据 HTML5 规范,在没有其他合适标签更合适时,才应该把
<b>标签作为最后的选项。HTML5 规范声明:应该使用h来表示标题,使用em标签来表示强调的文本,应该使用strong标签来表示重要文本,应该使用<mark>标签来表示标注的/突出显示的文本
图片加载优化
cssSprite(css精灵图)
多张零星的图片合并到一张大图上,减少请求图片的次数
Base64
可以将一副图片数据编码成一串字符串,使用该字符串代替图像地址。
图片的下载始终都要向服务器发出请求,而通过base64编码后,可以随着 HTML的下载同时下载到本地,类似于预渲染,减少 http 请求。
html5语义化标签
<time>:表示时间日期<mark>:用来标记高亮文字,背景颜色默认是黄色<progress>:<progress value="30" max="100"></progress>类似自带的组件,显示一个进度条,上面三个标签是行内元素,其他的都是块级元素
<details>:open属性表示默认展开
1 | <details open> |
<blockquote>:长文本引用,有默认边距以实现缩进效果
<figure> :通常用于标记嵌入内容(如图像、图表、照片、代码片段等)的容器,并且可以带有标题(使用 <figcaption> 标签)。
1 | <figure> |
CSS
background属性
下面属性只包括常见的属性
| 子属性 | 作用 | 示例值 |
|---|---|---|
background-color | 设置背景颜色 | #ff0000, rgba(255,0,0,0.5) |
background-image | 设置背景图片(可多个图层) | url("image.jpg"), linear-gradient(45deg, red, blue),所以说使用渐变色的时候其实是在给background-image属性赋值;最先定义的背景图会显示在顶部,最后定义的背景图会显示在底部 |
background-position | 定义背景图片的起始位置 | 第一个参数是水平方向的位置,第二个方向是垂直方向的位置;取值类型可以是百分比(相对容器宽高),关键字(left,right,center,top,bottom)和数值,相对的都是容器左上角的那个点,向下,向右为正方向;若只指定一个参数,那么第二个参数默认是center |
background-size | 控制背景图片的尺寸 | 第一个参数是宽度,第二个参数是高度;取值类型同样可以是百分比(相对容器宽高),关键字,和具体数值。cover(等比例缩放图片,直至完全覆盖容器), contain(等比例缩放图片,直至将要发生裁剪),使用关键字的时候,指定一个参数就好;100px 200px(指定元素的宽为100px,高为200px),如果只指定一个参数,第二个参数默认是auto,就是等比例缩放的意思;background-size: 100% 和 background-size: 100% auto 是等价的,表示高度随宽度等比例缩放。 |
background-repeat | 控制图片是否重复平铺 | no-repeat, repeat-x, space |
background-attachment | 设置背景是否随页面滚动 | scroll, fixed, local |
background 属性可以一次性声明多个子属性,顺序不严格固定,但通常按以下格式:
1 | .element { |
字体
在网页中加载字体通常使用 @font-face 规则,并通过 <style> 标签或外部 CSS 文件定义,并没有专门用来加载字体的HTML标签。
1 | @font-face { |
示例:
1 | <style> |
跨域影响:Web字体尤其容易受到CORS策略的影响。根据规范,为了防止字体被未经许可地使用,浏览器默认情况下不会从另一个源加载字体,除非服务器明确允许。
其他
浮动元素:浮动元素会默认转化成块级元素
私有属性前缀:
mozilla内核 (firefox,flock等) -moz
webkit内核(safari,chrome等) -webkit
opera内核(opera浏览器) -o
trident内核(ie浏览器) -ms(就是Microsoft微软的意思)
JS
逻辑中断
1 | console.log('foo' || 'bar') |
第一个输出'foo',因为第一个表达式就能确定整个表达式的真假,所以直接输出'foo'
第二个输出'bar',因为需要判断第二个表达式的值,才能确定表达式的值,所以输出'bar'
如果||左右2个表达式的布尔值都是false,则取最后一个表达式作为||表达式的值
要注意的是,返回的不是布尔值,这一点和其他编程语言有所不同
URL对象
1 | const obj = new URL('https://www.bilibili.com/?spm_id_from=333.337.0.0') |
传入一个url,返回一个url对象,我们需要了解这个url的各个属性,以及它的值
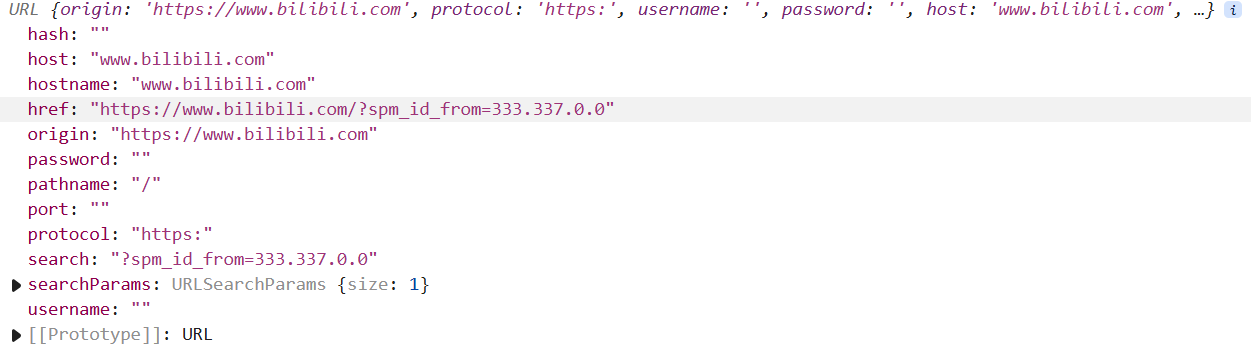
obj.href属性返回的就是传入URL构造函数的url。
hostname指的是URL中主机名的部分,即不包括端口号
host包括了主机名和端口号,port即url中的端口号,host=hostname+port
格式化unix时间戳
new Date()返回代表当前日期和时间的对象,这个对象包含了从1970年1月1日午夜(UTC)以来的毫秒数(也称为Unix时间戳的扩展形式),如果你需要从一个Date对象获取时间戳,可以通过调用getTime()方法来得到自1970年1月1日以来的毫秒数。- 或者直接使用
Date.now()这个静态方法来获得当前时间的时间戳(以毫秒为单位)。
格式化浮点数
关键点在于知不知道toFix方法
1 | 编辑试题描述 编写函数format实现金额按千分位分隔转化,如: |
async await
1 | let arr = [1, 2, 3, 4] |
依次输出5,1,2,3,4。console.log(5)并不会被阻塞,因为这段代码甚至不在async函数中,而且forEach会依次调用传入的async函数,这一过程是同步的,并不会被阻塞。
1 | let arr = [1, 2, 3, 4] |
依次输出5,1,2,3,4,其实上述for循环代码就等同于在全局作用域中写了4个定时器。
1 | let arr = [1, 2, 3, 4] |
依次输出5和4个undefined,因为最后定时器中的代码开始执行的时候,因为for循环先一步执行完毕,所以i=arr.length,所以后续访问arr[i]自然就因为下标越界获取不到元素返回undefined(在 JavaScript 中,数组下标越界不会直接报错,但会返回 undefined)。
缓存机制
1 | 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。 |
最终代码:
1 | class LRUCache { |
有序数组去重
1 | arr = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4] |
其中每次循环,数组的长度都会重新计算。
扁平化数组
1 | const case1 = [1, [2, 3], 4]; |
写递归函数主打一个相信
网络安全
- 什么是表单的跨站脚本攻击?
将时间戳转化成本地时间
1 | function timestampToLocalTime(timestamp) { |
其他
标识符:
只能由字母(A-Z, a-z)、数字(0-9)和下划线(_)还由美元符号构成。
标识符不能以数字开头,也不能包含特殊字符(如空格、
@、#等)避免使用 JavaScript 的关键字作为标识符,比如with。
var obj = / /是一个正则表达式,用来匹配一个空格。1
2
3
4
5
6var obj = / /; //用来匹配一个空格
console.log(obj.test("")); // 输出: false
console.log(obj.test(" ")); // 输出: true
console.log(obj.test("abc")); // 输出: false
console.log(obj.test("a bc")); // 输出: true暂时性死区
1
2
3
4
5
6
7var temp = 123
if (true) {
temp = 'abc'
let temp
console.log(temp)
}
console.log(temp)这段代码运行后,会报错,错误信息显示
Uncaught ReferenceError: Cannot access 'temp' before initializationlet声明的变量会产生块级作用域,而且在这个块级作用域中,在声明这个变量前的位置,不能访问这个变量,就像此处的,不能再声明temp前,访问temp,即便外面有一个var声明的temp,也会变得无法访问。简单的来说,只要在一个块级作用域中使用let声明了一个变量,无论这个变量在哪个位置声明,在这个块级作用域中,当访问同名变量的时候,访问的只能是这个let声明的变量。前置递增,后置递增
1
2var a = 10, b = 20, c = 4
console.log(++b + c + a++)前置递增 (
++b) 会先增加变量的值,并返回更新后的值。后置递增 (
a++) 会先返回变量的当前值,然后再增加变量的值。表达式的最终结果是
35,并且执行完后:a = 11,b = 21,c = 41
2
3var x = 10, y = 20
var z = x < y ? x++ : ++y
console.log(x, y, z)//输出11 20 10x<y为真,所以x++的值会被赋予给z,因为x是后置递增,所以会把递增前的值赋给z,然后递增;由于
++y不会被执行,所以y不会被改变。立即执行函数:立即执行函数(IIFE,Immediately Invoked Function Expression)本质上是一种函数表达式,并且它在定义的同时立即执行
1
2
3
4
5
6
7(function() {
// 函数体
})();
//或者
(function() {
// 函数体
}());object.freeze:
Object.freeze()是 JavaScript 中的一个方法,用于冻结对象。冻结的对象是指,不可扩展(不能向对象添加新的属性)、不可修改属性(不能修改现有属性的值)、不可删除属性(不能删除对象的属性),不可重新配置(不能更改现有属性的特性,如writable、configurable等)的对象。换句话说,冻结后的对象是只读的。返回值:返回被冻结的对象(即传入的对象本身)。
object.freeze()只会浅层冻结对象,也就是说,如果对象的某个属性是一个嵌套对象,那么嵌套对象不会被自动冻结。一旦对象被冻结,就无法解冻,冻结不影响原型链上的属性。- 冻结后只可读,且无法解冻
- 冻结只是浅层冻结
可以使用
Object.isFrozen()方法来检查一个对象是否被冻结。


